TL;DR
Artificial Analysis vừa công bố benchmark agentic performance cho Speech to Speech (S2S) models sử dụng 𝜏-Voice. Kết quả cho thấy ngay cả model mạnh nhất — xAI Grok Voice Think Fast 1.0 — cũng chỉ giải quyết được 52.1% tình huống customer service thực tế. Khoảng cách so với text-based agents vẫn rất lớn.
Voice Channels: Kênh Giao Tiếp Đầy Thách Thức
Trong khi text-based agents ngày càng tiến bộ, voice agents vẫn đang vật lộn với những khó khăn đặc thù của kênh thoại:
- Challenging accents: Các giọng địa phương, phương ngữ đa dạng
- Background noise: Tiếng ồn môi trường ảnh hưởng đến nhận dạng giọng nói
- Packet loss: Mất gói tin trong mạng làm gián đoạn audio stream
- Fast responses: Yêu cầu phản hồi nhanh để duy trì tính tự nhiên của cuộc trò chuyện
- Long multi-turn consistency: Duy trì context qua nhiều lượt hội thoại
- Reliable tool use: Gọi API và xử lý dữ liệu chính xác trong khi nói chuyện
🚨 Reality Check
Ngay cả trong điều kiện audio sạch, một số model hoạt động tốt hơn đáng kể — nhưng điều kiện thực tế vẫn là thách thức. Đây là khoảng cách ý nghĩa so với frontier text-based agents trên cùng một task.
𝜏-Voice: Benchmark Cho Voice Agents
Artificial Analysis xây dựng benchmark dựa trên 𝜏-Voice (Ray, Dhandhania, Barres & Narasimhan, 2026) — mở rộng 𝜏²-bench sang voice modality để đánh giá S2S models trên các tác vụ customer service thực tế.
Multi-Turn Instruction Following
Đo khả năng tuân theo hướng dẫn qua nhiều lượt hội thoại, không chỉ một câu hỏi — một câu trả lờì.
Simulated Customer
Kết hợp LLM-driven decision model với realistic audio synthesis: accents đa dạng, background noise, packet loss theo điều kiện mạng thực.
Tool Use Against Systems
Đánh giá khả năng sử dụng công cụ để tương tác với hệ thống customer service mô phỏng trong quá trình hội thoại.
Deterministic Evaluation
Task success được xác định bằng kiểm tra hành động mong đợi và trạng thái database cuối cùng — khách quan, không subjective.
3 Domain Đánh Giá
Benchmark sử dụng 𝜏²-bench base task split across ba lĩnh vực:
- Airline (50 scenarios): Đổi chuyến bay, rebooking theo chính sách...
- Retail (114 scenarios): Tranh cãi phí, xử lý trả hàng...
- Telecom (114 scenarios): Giải quyết vấn đề hóa đơn, troubleshooting dịch vụ...
Scores là trung bình của 3 independent pass@1 trials, đánh giá trong điều kiện audio thực tế.
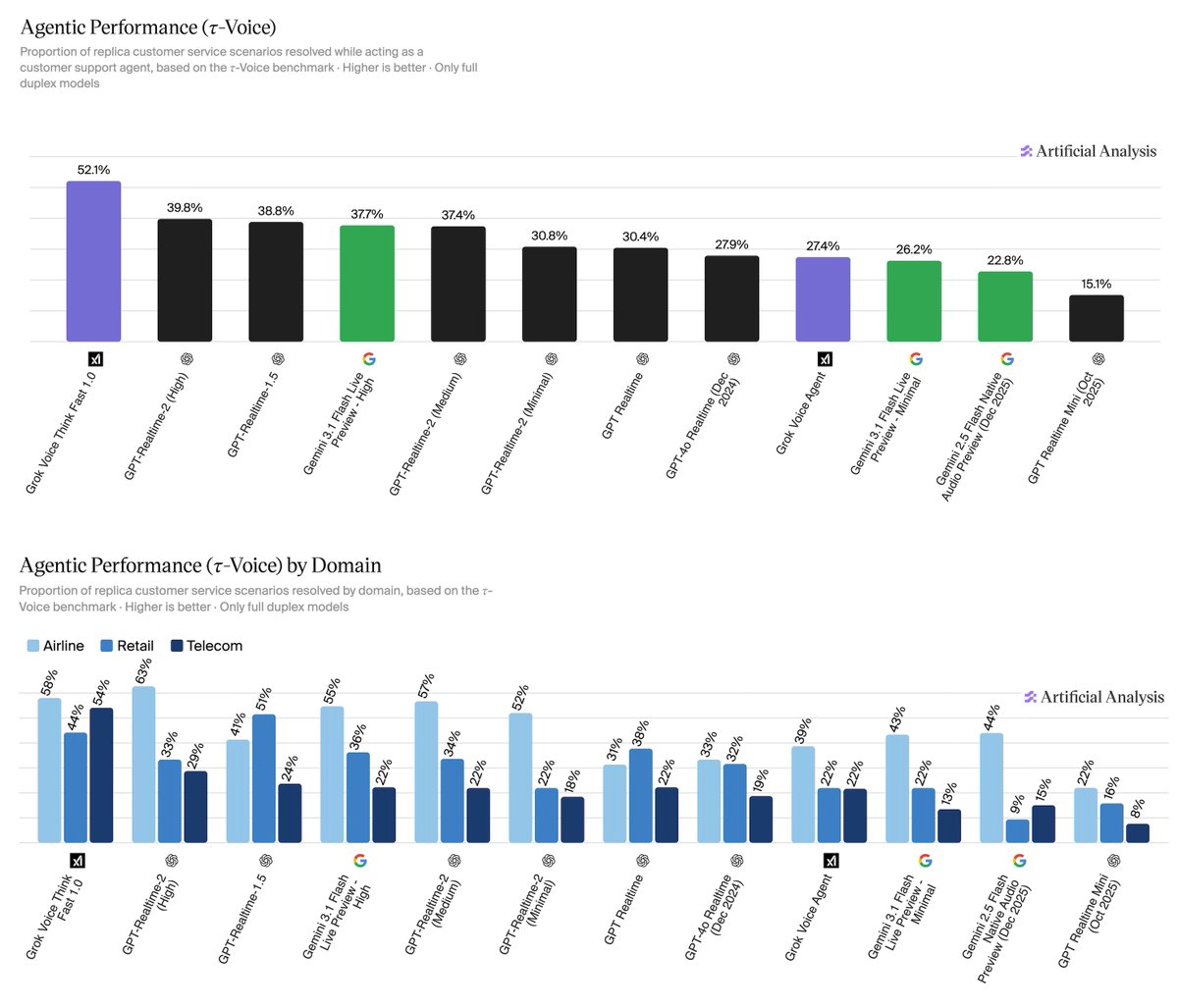
Bảng Xếp Hạng
| Hạng | Model | Tỷ Lệ Thành Công | Thờì Gian TB |
|---|---|---|---|
| 🥇 1 | xAI Grok Voice Think Fast 1.0 | 52.1% | 5.6 phút |
| 2 | OpenAI GPT-Realtime-2 (High) | 39.8% | 3.0 phút |
| 3 | OpenAI GPT-Realtime-1.5 | 38.8% | 4.8 phút |
| 4 | Gemini 3.1 Flash Live Preview — High | 37.7% | 3.8 phút |
Điểm Đáng Chú Ý
Grok Voice Think Fast 1.0 dẫn đầu với 52.1% nhưng cũng có thờì gian hội thoại trung bình dài nhất (5.6 phút, đứng thứ hai tổng thể). Điều này cho thấy model cần nhiều thờì gian hơn để đạt được kết quả tốt — một trade-off giữa accuracy và customer experience.
Các model của OpenAI (GPT-Realtime-2 và 1.5) xếp thứ 2 và 3 với tỷ lệ thành công ~39%, nhưng có thờì gian hội thoại ngắn hơn đáng kể (3.0 và 4.8 phút). Thờì gian hội thoại ảnh hưởng trực tiếp đến operational cost — mỗi phút thêm là chi phí API và infrastructure.
Gemini 3.1 Flash Live Preview — High đứng thứ 4 với 37.7% và 3.8 phút, cho thấy Google cũng đang cạnh tranh mạnh trong lĩnh vực này.
Bổ Sung Cho Các Benchmark Khác
𝜏-Voice không đứng một mình mà bổ sung cho hệ sinh thái benchmark của Artificial Analysis:
- Big Bench Audio: Đo intelligence của models
- Conversational Dynamics (Full Duplex Bench subset): Đo conversational naturalness — tính tự nhiên của hội thoại
- 𝜏-Voice: Đo agentic performance trong customer service scenarios thực tế
Đánh Giá Của Escbase
Benchmark này đặt ra một tiêu chuẩn khắt khe và thực tế cho voice agents. Việc sử dụng deterministic checks thay vì human evaluation giúp kết quả khách quan và reproducible.
Tuy nhiên, 52.1% là con số đáng lo ngại cho bất kỳ doanh nghiệp nào muốn triển khai voice agent trong customer service. Điều này có nghĩa là cứ 2 cuộc gọi thì gần 1 cuộc sẽ không được giải quyết thành công — một tỷ lệ không chấp nhận được trong production.
Speech to Speech là modality đang phát triển nhanh. Artificial Analysis dự đoán rankings sẽ thay đổi khi các model mới được thêm vào và robustness được cải thiện. Nhưng hiện tại, voice agents vẫn chưa sẵn sàng thay thế hoàn toàn text-based agents hay human agents trong customer service.
💡 Điểm cần theo dõi
Conversation duration ảnh hưởng đến cả customer experience lẫn operational cost. Các model cần cân bằng giữa accuracy và speed — không chỉ giải quyết được vấn đề mà còn phải làm nhanh.
Kết Luận
Benchmark 𝜏-Voice từ Artificial Analysis cho thấy voice agents vẫn còn một chặng đường dài trước khi có thể rival text-based agents trong customer service. Dù Grok Voice dẫn đầu với 52.1%, con số này vẫn quá thấp cho production deployment.
Với 278 scenarios across 3 domains và evaluation dựa trên deterministic checks, 𝜏-Voice là một bước tiến quan trọng trong việc đo lường thực tế của voice AI. Các nhà phát triển và doanh nghiệp cần theo dõi sát sao sự tiến bộ này — vì voice là kênh giao tiếp tự nhiên nhất, và khi nó sẵn sàng, impact sẽ là transformative.