⚡ Tóm tắt nhanh
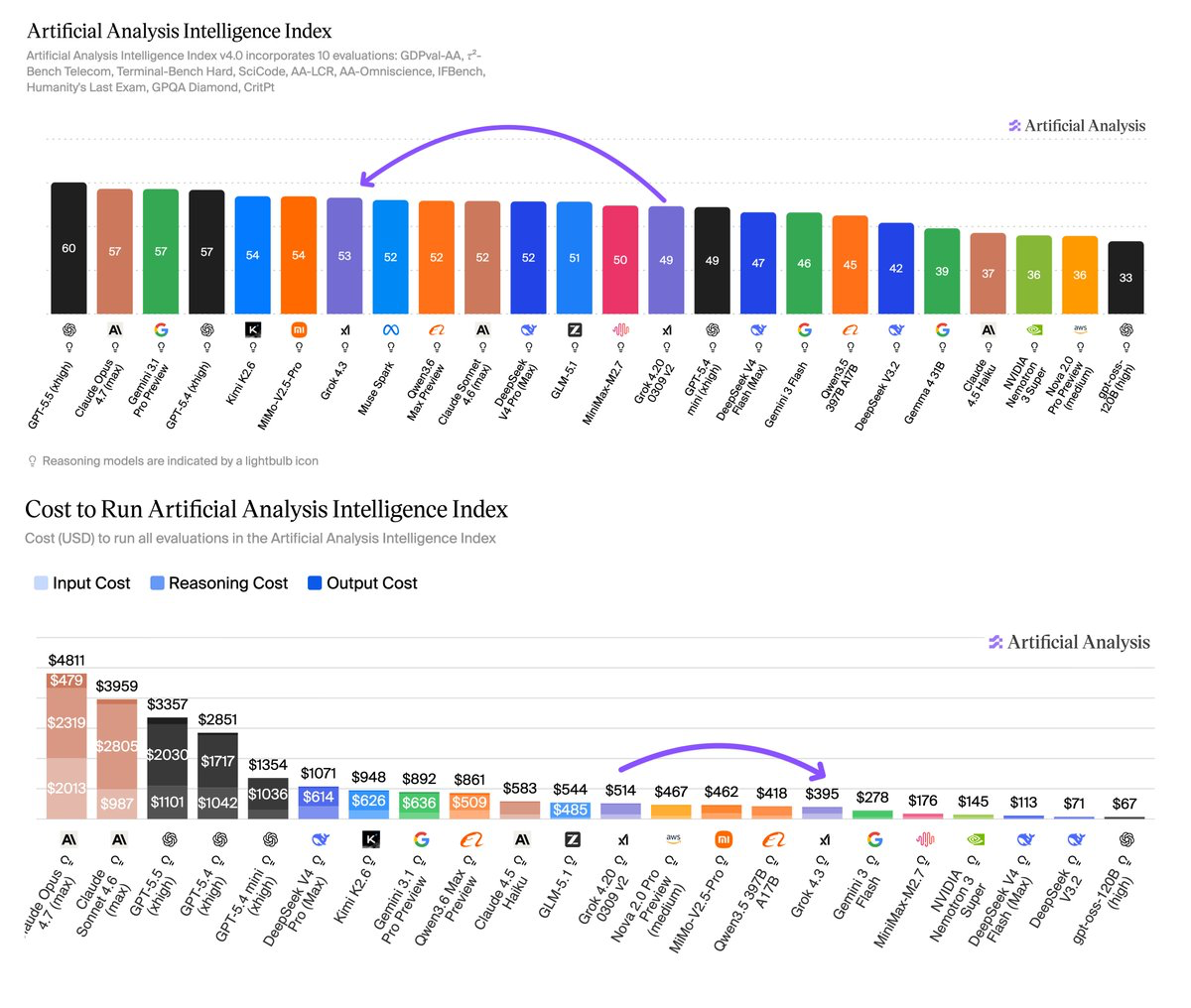
xAI ra mắt Grok 4.3 với điểm số AT Intelligence Index đạt 53, giá input $1.25/1M tokens và output $2.50/1M tokens — rẻ hơn 4–12 lần so với GPT-5.5 ($5/$30) và Claude Opus 4.7 ($5/$25). Model này ngồi trên Pareto frontier intelligence vs cost, vượt Claude Sonnet 4.6, Gemini 3.1 Pro, Muse Spark và Kimi K2.5, nhưng vẫn kém GPT-5.5 (Index 60) ~276 Elo và Opus 4.7 (Index 57) ~150 Elo. Cộng đồng phản ứng tích cực về hiệu quả chi phí, nhưng một số đặt câu hỏi rằng các benchmark có thể chỉ tối ưu cho test.
Hôm 30/4/2026, xAI chính thức công bố Grok 4.3 — bản nâng cấp tiếp theo của model lớn nhất họ, với những cải thiện rõ rệt về cả intelligence và chi phí. Theo Artificial Analysis Intelligence Index, Grok 4.3 đạt 53 điểm, cao hơn 4 điểm so với Grok 4.20, và vượt lên trên cả Claude Sonnet 4.6 và Gemini 3.1 Pro tại thời điểm ra mắt.
1.1 So sánh trực tiếp: GPT-5.5, Claude Opus 4.7 và Grok 4.3 trên AT Index và giá
Để đặt Grok 4.3 vào bối cảnh, hãy so sánh trực tiếp với hai model frontier hiện tại — GPT-5.5 (OpenAI) và Claude Opus 4.7 (Anthropic) — trên thang điểm Artificial Analysis (AT) Intelligence Index, một chỉ số tổng hợp từ nhiều benchmark đánh giá reasoning, coding, và khả năng agentic.
| Model | AT Index* | Input ($/1M) | Output ($/1M) | Context |
|---|---|---|---|---|
| Grok 4.3 (xAI) | 53 | $1.25 | $2.50 | 1M |
| GPT-5.5 (OpenAI) | 60 | $5.00 | $30.00 | 1.05M |
| Claude Opus 4.7 (Anthropic) | 57 | $5.00 | $25.00 | 1M |
*Artificial Analysis Intelligence Index: thang điểm tổng hợp từ các benchmark MMLU, GPQA, coding, agentic tasks — cao hơn = intelligence mạnh hơn.
Phân tích nhanh: GPT-5.5 dẫn đầu về pure intelligence (60 điểm), Opus 4.7 đứng thứ hai (57), Grok 4.3 là 53. Tuy nhiên về chi phí, Grok 4.3 vượt trội: input rẻ hơn 4 lần so với hai đối thủ ($1.25 vs $5.00), và output rẻ hơn 10–12 lần ($2.50 vs $25–30). Sự chênh lệch này lý giải tại sao Grok 4.3 có thể ngồi trên Pareto frontier — nó đánh đổi một phần intelligence (~7–11 điểm Index) để đạt lợi thế chi phí rất lớn, phù hợp cho các workflow có volume cao và ngân sách hạn chế.
1. Chi phí thấp hơn, điểm số cao hơn: Pareto frontier mới
Điểm đáng chú ý nhất là Grok 4.3 vừa tăng điểm vừa giảm giá. Theo tính toán của Artificial Analysis, chi phí để chạy toàn bộ AI Index benchmark cho Grok 4.3 là $395 — khoảng 20% thấp hơn so với Grok 4.20 0309 v2, cho dù model này sử dụng nhiều output token hơn (~44%). Lý do là xAI cắt giảm giá token đầu vào khoảng 37.5% và token đầu ra khoảng 58.3%. Điều này đưa Grok 4.3 trở thành một trong những model có chi phí thấp nhất ở mức intelligence tương ứng.
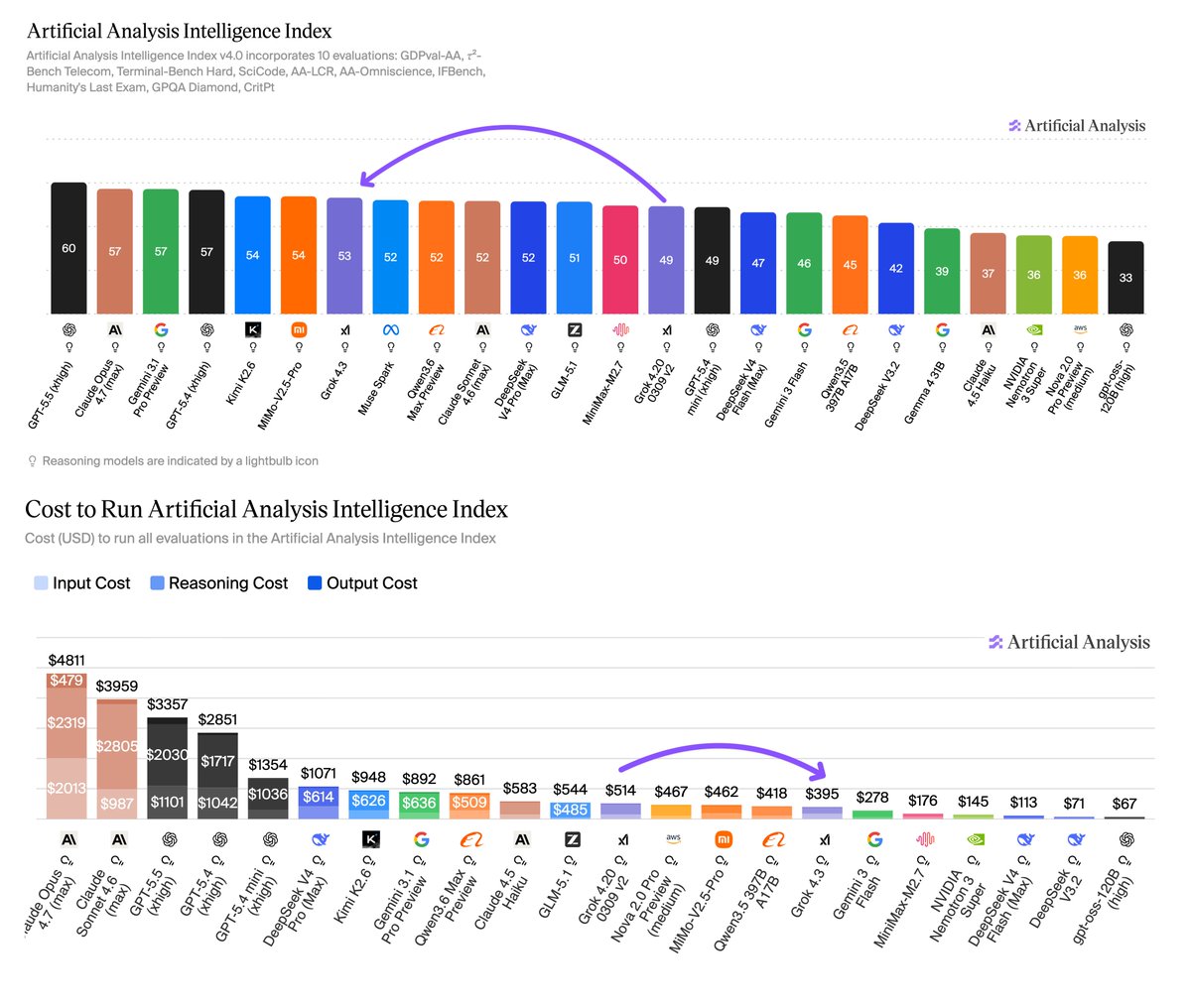
Chuỗi cải thiện này giúp Grok 4.3 "ngồi" vững trên Pareto frontier — nghĩa là khó có model nào vừa thông minh hơn vừa rẻ hơn cùng lúc. Điều này trở thành lợi thế cạnh tranh quan trọng với các nhà cung cấp API, nơi chi phí inference chiếm phần lớn operational expense.
2. Agentic tasks và instruction following tăng mạnh
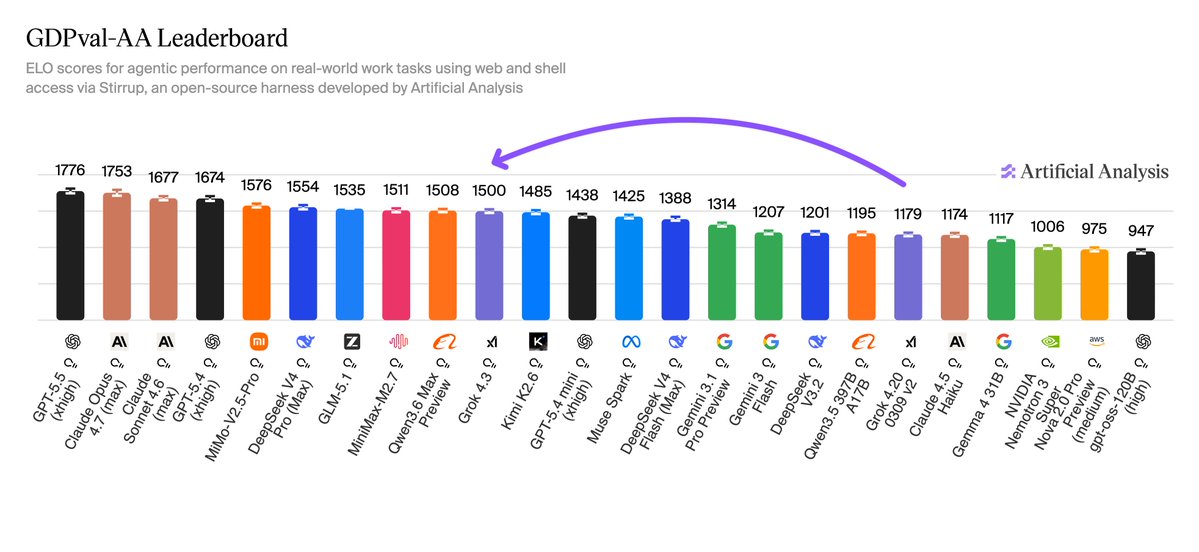
Ngoài tổng hợp điểm số, Grok 4.3 ghi nhận cải thiện lớn ở các bài tập agentic thực tế. Cụ thể, trên GDPval-AA — benchmark đánh giá khả năng xử lý giá trị kinh tế và ra quyết định — Grok 4.3 đạt ELO 1500, tăng 321 điểm so với 1179 của Grok 4.20, vượt Gemini 3.1 Pro Preview, Muse Spark, GPT-5.4 mini (xhigh) và Kimi K2.5. Chỉ có GPT-5.5 (xhigh) vẫn dẫn đầu với ELO 1776, cách Grok 4.3 khoảng 276 Elo (xác suất thắng ~17% theo công thức Elo).
Trong lĩnh vực instruction following và customer support, Grok 4.3 đạt 98% trên τ²-Bench Telecom (+5 điểm), ngang với GLM-5.1, và giữ nguyên 81% trên IFBench — cho thấy độ ổn định trong các tác vụ có cấu trúc.
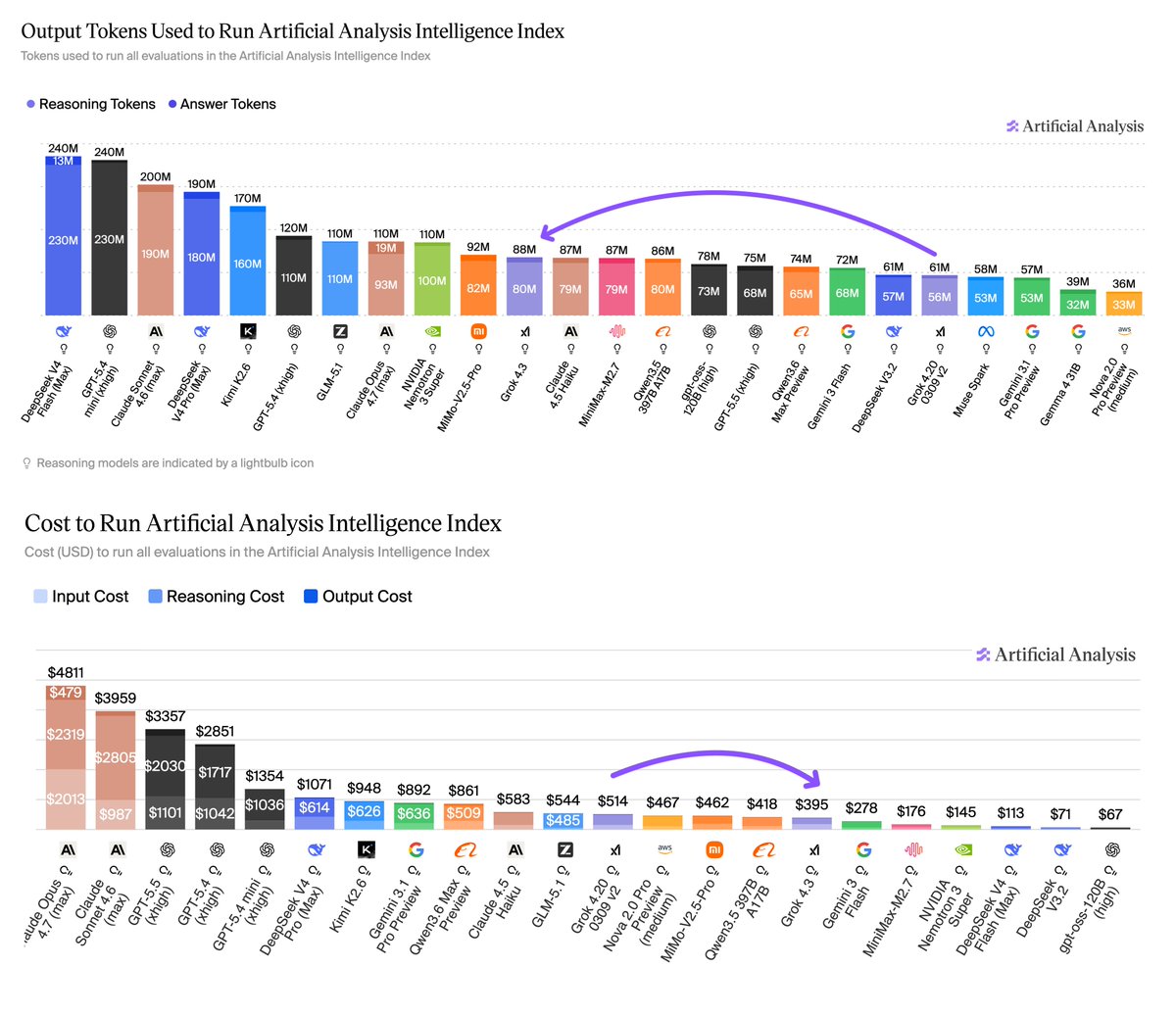
Một chi tiết thú vị: Grok 4.3 sử dụng ~44% nhiều output token hơn Grok 4.20 để chạy cùng benchmark, nhưng nhờ giá token giảm mạnh (58.3% output, 37.5% input) nên tổng chi phí vẫn giảm ~20%. Điều này cho thấy model có thể "nói nhiều hơn" nhưng vẫn tiết kiệm chi phí.
3. Trade-off: chính xác tăng, nhưng hallucination cũng tăng
Một vấn đề đáng lưu ý là Grok 4.3 ghi nhận +8 điểm trên AA-Omniscience Accuracy — tức là khả năng trả lời đúng các câu hỏi đa dạng, nhưng đồng thời cũng giảm 8 điểm trên AA-Omniscience Non-Hallucination Rate. Nói cách khác, model trở nên thông minh hơn nhưng cũng có xu hướng bịa thông tin nhiều hơn một chút. Trong khi Grok 4.20 vẫn dẫn đầu về khả năng không ảo giác, các đối thủ như MiMo-V2.5-Pro cũng thể hiện sự cân bằng tốt hơn về mặt này.
Trade-off này không bất ngờ: khi model mở rộng khả năng suy luận, việc kiểm soát hoàn toàn tính chính xác là thách thức. Đối với các ứng dụng yêu cầu độ tin cậy cao, đây là yếu tố cần cân nhắc.
4. Phản ứng cộng đồng: khen ngợi hiệu quả, hoài nghi tính thực tế
Cộng đồng AI trên X phản ứng nhanh và khá phân hóa. Nhiều người khen về chiến lược định giá phá cựa của xAI:
— @WarScopeGlobal
@AlenaaBonya nhận xét sắc bén:
Tuy nhiên, không thiếu những tiếng nói thận trọng. @thulani_kate đặt câu hỏi về tính khách quan của benchmark:
Một số người dùng khác như @thingsnoticed nhận định:
5. Điều gì còn thiếu, và Grok 4.3 thực sự "đáng đồng tiền"?
Mặc dù các con số ấn tượng, câu chuyện về Grok 4.3 vẫn còn vài điểm cần tự vấn:
- Benchmark sang thực tế: GDPval-AA, τ²-Bench, IFBench đều là bài test có cấu trúc. Liệu model có giữ hiệu năng khi xử lý workflow đa bước, với context dài, thông tin động và user intent phức tạp không?
- Trade-off hallucination: Việc non-hallucination rate giảm 8 điểm có thể ảnh hưởng đến độ tin cậy trong các tác vụ sáng tạo nội dung, phân tích pháp lý, hoặc báo cáo?
- So sánh với local models: Một số ý kiến chỉ ra rằng local models chạy trên hardware sẵn có không tốn phí inference, liệu Grok 4.3 có đủ rẻ để thuyết phục người dùng chuyển đổi?
- Token usage: Grok 4.3 dùng ~44% nhiều output token hơn Grok 4.20. Điều này có nghĩa là throughput thực tế sẽ chậm hơn, và hybrid cost (token count × giá) vẫn cần đánh giá từng use-case.
Dù vậy, việc đạt được cả hai mục tiêu — tăng intelligence và giảm chi phí — trong một release là cột mốc đáng chú ý. Trong thị trường AI đang nóng, nơi các model lớn thường "nặng" và đắt đỏ, Grok 4.3 chứng tỏ rằng xAI đang theo đuổi chiến lược "efficiently smart" thay vì "bigger is better".
🎯 Chốt một câu
Grok 4.3 không chỉ là bản nâng cấp điểm số — nó là minh chứng rằng AI có thể vừa thông minh hơn vừa rẻ hơn, và Pareto frontier mới này sẽ gây áp lực lớn lên các đối thủ trong cuộc đua giá và hiệu năng suốt năm 2026.
Source: bài đăng và thread từ @ArtificialAnlys trên X, kèm theo các biểu đồ và số liệu từ Artificial Analysis. Ảnh minh họa được trích từ tweet gốc.