⚡ Tóm tắt nhanh
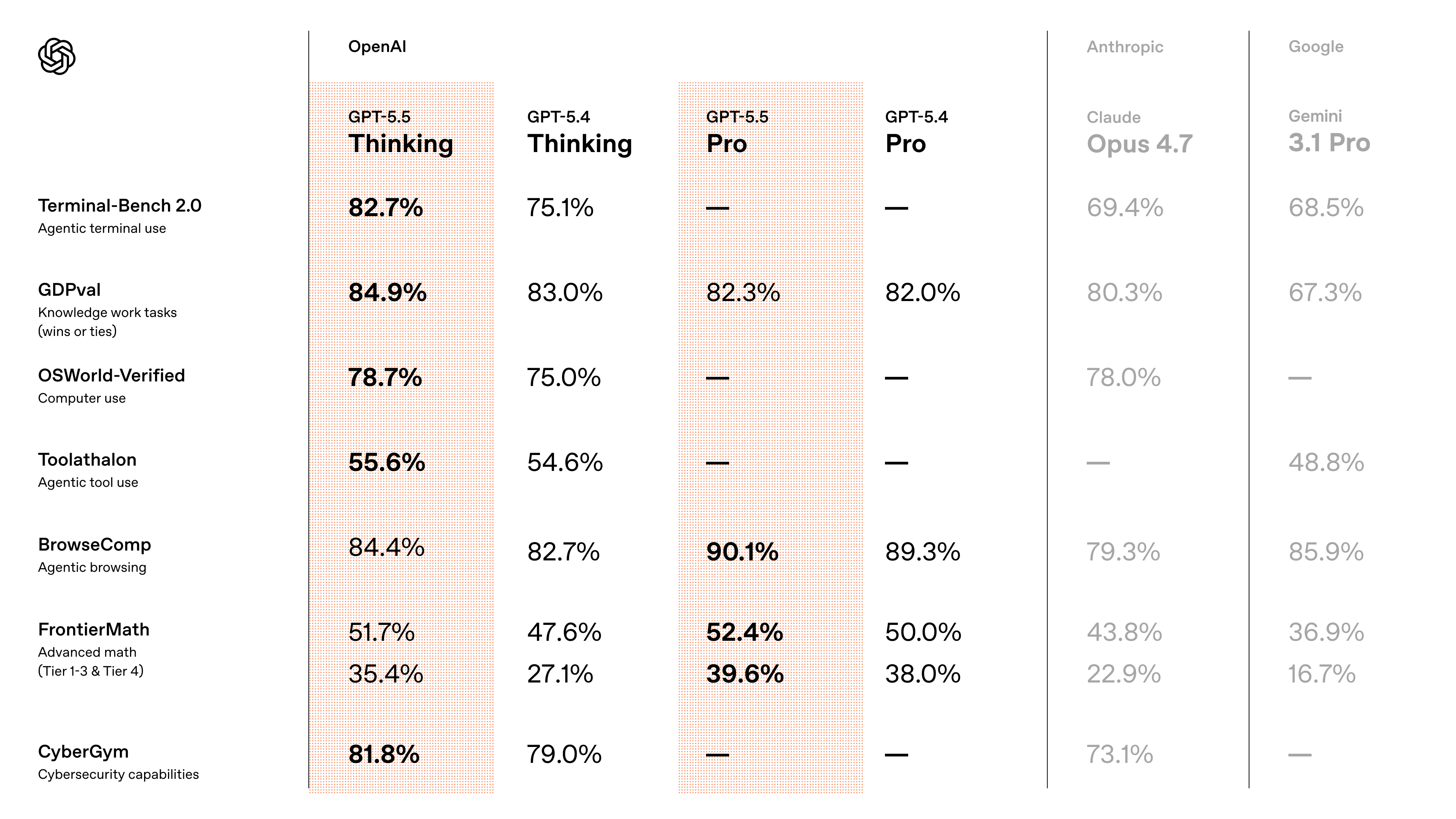
OpenAI ra GPT-5.5 không theo kiểu khoe model mới cho vui. Họ quăng thẳng một bảng so sánh đặt GPT-5.5 cạnh Claude Opus 4.7 và Gemini 3.1 Pro, rồi chốt thông điệp rất rõ: đây là model mạnh nhất của họ cho real work, agent workflows và computer use. Cú khó chịu nhất nằm ở chỗ OpenAI không chỉ khoe điểm cao hơn trên các benchmark mang mùi công việc thật, mà còn nói GPT-5.5 giữ latency ngang GPT-5.4.
Nếu nhìn vào ảnh benchmark OpenAI tự chọn để tung ra đầu tiên, thông điệp gần như không cần giải thích: GPT-5.5 không chỉ muốn hơn GPT-5.4, mà còn muốn đóng đinh vị thế trước Claude Opus 4.7 và Gemini 3.1 Pro trong cuộc đua AI cho công việc thật.
Đó là chi tiết đáng chú ý nhất của cả launch này. OpenAI không né đối thủ, không so mơ hồ, mà đặt tên thẳng các model cạnh tranh ngay trong chart rồi kéo cuộc chơi về những bài test nghe rất “đi làm”: coding, browse, tool use, OS tasks, frontier math, cyber. Nói cách khác, họ không bán GPT-5.5 như model trả lời hay hơn vài câu hỏi benchmark. Họ bán nó như một hệ thực thi công việc trên máy tính.
Video launch gốc từ tweet của OpenAI. Mình nhúng thẳng video thật vào bài.
1. OpenAI đang biến benchmark chart thành chiến thư gửi Opus và Gemini
Chart trong thread không phải ảnh minh họa cho có. Nó là đòn định vị rất có chủ đích. Khi OpenAI đem GPT-5.5 đặt cạnh Claude Opus 4.7 và Gemini 3.1 Pro ở các bài test như Terminal-Bench 2.0, GDPval, OSWorld-Verified, BrowseComp, FrontierMath và CyberGym, họ đang nói một câu rất rõ: nếu cuộc đua tiếp theo là AI làm việc thật trên máy tính, GPT-5.5 mới là con họ muốn ngồi ghế đầu.
Theo thread và trang giới thiệu, GPT-5.5 mạnh ở một nhóm việc rất cụ thể:
- viết và debug code,
- research online,
- phân tích dữ liệu,
- tạo document và spreadsheet,
- operate software,
- di chuyển qua nhiều tool cho tới khi task hoàn tất.
Điểm này quan trọng vì nó cho thấy OpenAI đang đẩy model ra khỏi framing kiểu “reasoning engine” thuần túy. GPT-5.5 được đóng gói như một mô hình dành cho execution-heavy work.
2. Điểm đáng tiền nhất: nhanh hơn về cảm giác sử dụng, không chỉ mạnh hơn trên giấy
Một trong những claim đáng chú ý nhất của OpenAI là GPT-5.5 giữ per-token latency ngang GPT-5.4, nhưng lại perform tốt hơn trên gần như mọi eval họ đem ra. Đó là claim rất quan trọng, vì model mạnh hơn nhưng chậm đi thường chỉ hợp cho demo hoặc vài use case hẹp.
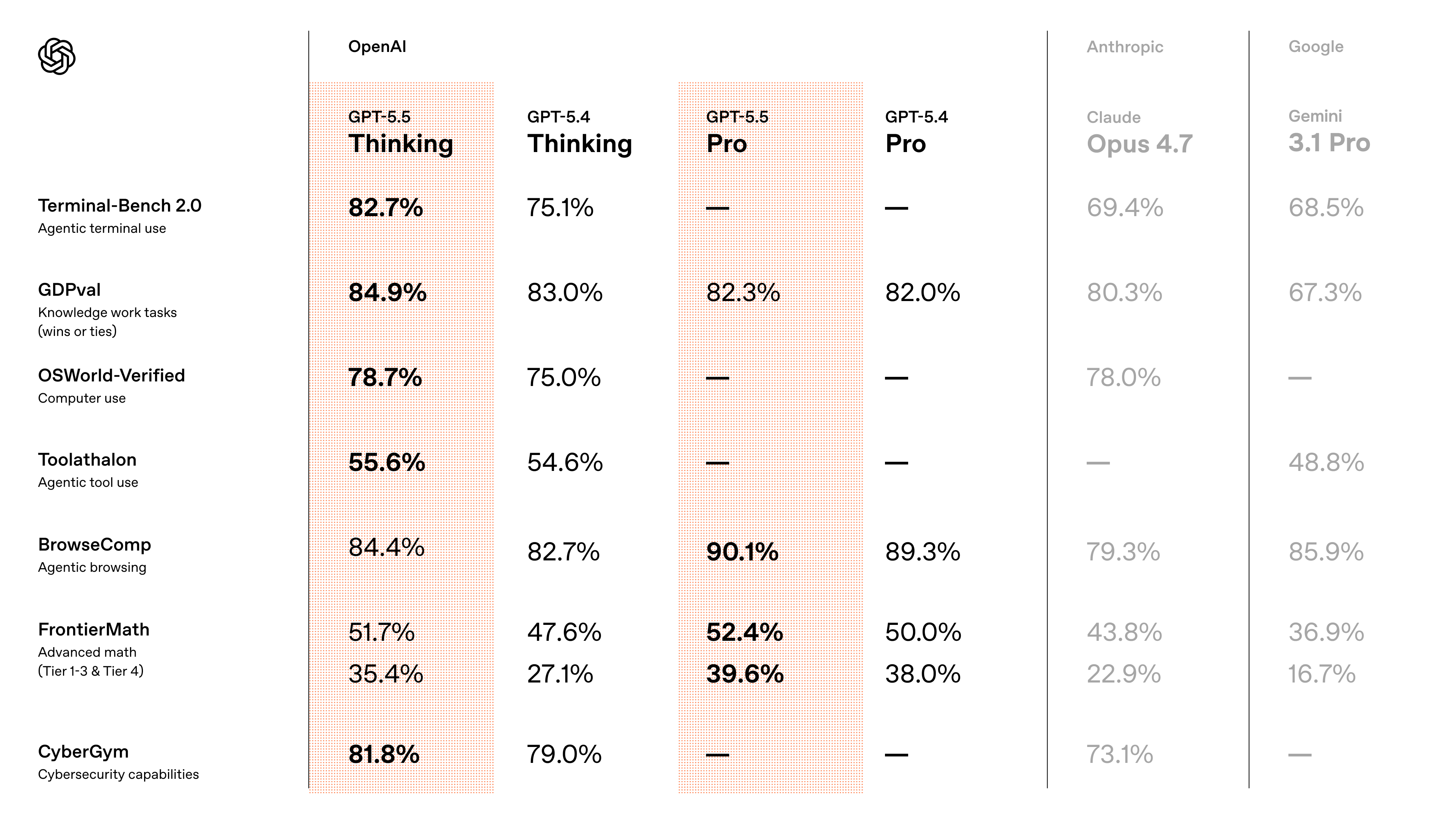
Ảnh từ thread cho thấy OpenAI đang cố bán một câu chuyện kép: mạnh hơn nhưng không chậm hơn, thậm chí còn token-efficient hơn trên Codex tasks.
Trong thế giới dev tools và agent workflows, cái người dùng cảm nhận không phải FLOPs hay benchmark abstract. Họ cảm nhận:
- nó có hiểu việc mình muốn làm không,
- có tự đi tiếp mà không khựng sớm không,
- có cần retry nhiều lần không,
- và chờ có quá bực không.
Nếu GPT-5.5 thực sự giữ tốc độ mà tăng độ bền trong các workflow dài, đó mới là phần đắt.
3. Codex mới là sân khấu thật của GPT-5.5
OpenAI nói thẳng rằng gains rõ nhất của GPT-5.5 nằm ở agentic coding, computer use, knowledge work và early scientific research. Nói cách khác, GPT-5.5 không được sinh ra để thắng mấy câu hỏi trivia. Nó được sinh ra để đi đường dài.
Trên trang giới thiệu, OpenAI dồn khá nhiều hỏa lực cho câu chuyện Codex:
- mạnh hơn ở Terminal-Bench 2.0,
- tốt hơn ở long-horizon coding,
- dùng ít token hơn trên cùng task,
- giữ context tốt hơn qua codebase lớn,
- và dự đoán trước testing / review needs tốt hơn.
Đây là framing rất rõ: Codex không còn chỉ là “IDE assistant”. Nó đang được OpenAI đẩy thành môi trường làm việc nơi model có thể mang phần implementation nặng hơn của engineering.
🧠 Điểm mấu chốt
OpenAI đang nói rằng model tốt không chỉ là model trả lời đúng hơn. Model tốt là model có thể cầm một đoạn việc đủ lớn, dùng tool, tự check và đi hết quãng đường mà trước đây người dùng phải giám sát liên tục.
4. Từ coding sang knowledge work: OpenAI đang tổng quát hóa cùng một primitive
Phần thú vị là OpenAI không dừng ở coding. Họ nhấn rằng cùng các năng lực đó đang lan sang knowledge work:
- research,
- information synthesis,
- document-heavy tasks,
- spreadsheet modeling,
- presentation và business reporting.
Nếu đọc kỹ, logic sản phẩm ở đây rất đẹp: dù là code, tài chính hay khoa học, primitive cốt lõi vẫn là một thứ giống nhau — model hiểu intent, kéo context, gọi tool, kiểm tra output và hoàn tất task trên máy tính.
Đó là lý do mình nghĩ “computer work” mới là từ khóa thật của GPT-5.5. OpenAI đang gom nhiều category vốn nhìn khác nhau vào cùng một khung năng lực.
5. Early scientific research là tín hiệu chiến lược lớn hơn nhiều người tưởng
Trang giới thiệu dành hẳn một đoạn dài cho scientific workflows, GeneBench, BixBench, toán học và cả các case dùng trong genomics, drug discovery, algebraic geometry. Đây không phải phụ lục cho vui. Đây là tín hiệu OpenAI muốn GPT-5.5 được nhìn như một co-scientist primitive, không chỉ là office worker primitive.
Tất nhiên, mấy claim kiểu “bona fide co-scientist” cần đọc với sự dè chừng lành mạnh. Nhưng việc họ ưu tiên scientific research trong launch nói lên một tham vọng rất rõ: nếu model đã đủ bền để reasoning qua dữ liệu mơ hồ, confounders, QC failures và multi-stage analysis, thì nó sẽ có cơ hội chen vào những workflow tri thức có giá trị cực cao.
⚠️ Chỗ cần tỉnh táo
Benchmark và testimonial vẫn chỉ là benchmark với testimonial. Điều đáng hỏi hơn là GPT-5.5 có ổn định đến đâu khi đụng dữ liệu bẩn, quy trình đặc thù và constraint của từng tổ chức thật. “Thông minh hơn” không tự động đồng nghĩa “đáng tin hơn” trong mọi setting.
6. Rollout và pricing cũng là một phần câu chuyện
Theo thread, GPT-5.5 đang rollout cho Plus, Pro, Business và Enterprise trên ChatGPT và Codex; còn GPT-5.5 Pro dành cho Pro, Business, Enterprise trong ChatGPT. Trang OpenAI còn nói API sẽ tới “very soon”, vì serving model này ở quy mô API đòi hỏi safeguard khác.
Chi tiết này khá quan trọng. Nó cho thấy OpenAI đang ưu tiên rollout nơi họ kiểm soát được environment và hành vi dùng tốt hơn — đặc biệt là ChatGPT và Codex — trước khi bung sang API rộng rãi. Nói cách khác: GPT-5.5 không chỉ là model launch, mà là deployment strategy launch.
7. Chốt lại
GPT-5.5 đáng chú ý không chỉ vì mạnh hơn GPT-5.4 hay vì có thêm vài điểm benchmark đẹp. Nó đáng chú ý vì OpenAI đang cố định nghĩa lại model frontier như một công cụ để làm việc trên máy tính, chứ không chỉ để trả lời tốt hơn.
Khi một model được tối ưu cho goal understanding, tool use, self-checking, long-horizon completion và latency đủ thấp để dùng thật, nó bắt đầu trở thành một primitive sản phẩm mới. Không phải chatbot. Không chỉ reasoning engine. Mà là một lớp thực thi công việc số.
🎯 Chốt một câu
GPT-5.5 không chỉ là bản nâng cấp model. Nó là nỗ lực của OpenAI để biến “computer work” thành giao diện mặc định tiếp theo của AI.
Source: thread của OpenAI và trang giới thiệu GPT-5.5.