⚡ Tóm tắt nhanh
Xiaomi vừa tung MiMo-V2.5 và MiMo-V2.5-Pro với một thesis rất rõ: open-source agent muốn đáng dùng thì không chỉ cần benchmark đẹp, mà còn phải chạy dài hơi, gọi tool bền, hiểu đa phương thức và dùng ít token hơn ở cùng mặt bằng hiệu năng. Khi chính Xiaomi đặt MiMo-V2.5-Pro vào khung so với Claude Opus 4.6, GPT-5.4 và bản thường thì so sát Gemini 3.1 Pro, câu chuyện lập tức hấp dẫn hơn nhiều.
Thread launch của Xiaomi MiMo khá dày thông tin nhưng nếu bóc kỹ thì họ đang push một narrative rất cụ thể: open-source agents đã tiến tới mức không chỉ so benchmark với frontier models như Claude Opus 4.6, GPT-5.4 hay Gemini 3.1 Pro, mà còn bắt đầu cạnh tranh ở cost efficiency trên các long-horizon tasks.
Nói dễ hiểu: không còn là cuộc chơi “model nào thông minh hơn một chút”, mà là “model nào đủ mạnh để làm việc thật, đủ rẻ để deploy thật, và đủ bền để không chết giữa đường”.
1. Xiaomi đang ra mắt hai model, nhưng chỉ có một thông điệp lớn
Trong thread, Xiaomi chia MiMo-V2.5 series thành hai nhánh khá rõ:
- MiMo-V2.5-Pro cho các task agent dài, khó, cần reasoning sâu và nhiều tool calls.
- MiMo-V2.5 cho các scenario general-purpose hơn, nhanh hơn, rẻ hơn và có native omni-modal.

Xiaomi tự chia rất rõ vai trò: Pro cho long-horizon tasks khó, bản thường cho tốc độ + multimodality.
Nhìn bề ngoài thì đây là cách chia tier model khá quen. Nhưng cái đáng chú ý là Xiaomi không bán chúng như “một bản mạnh, một bản yếu hơn”. Họ bán nó như hai lời giải cho hai bài toán khác nhau:
- bài toán khó nhất cần độ lì và chiều sâu,
- và bài toán production cần tốc độ, modality và hiệu quả chi phí.
Đó là framing khôn. Vì ở giai đoạn này, model nào cũng có thể khoe benchmark. Cái khó hơn là giải thích vì sao người dùng phải chọn model A cho case này và model B cho case kia.
2. MiMo-V2.5-Pro muốn được nhìn như một con agent thật sự biết làm việc dài hơi
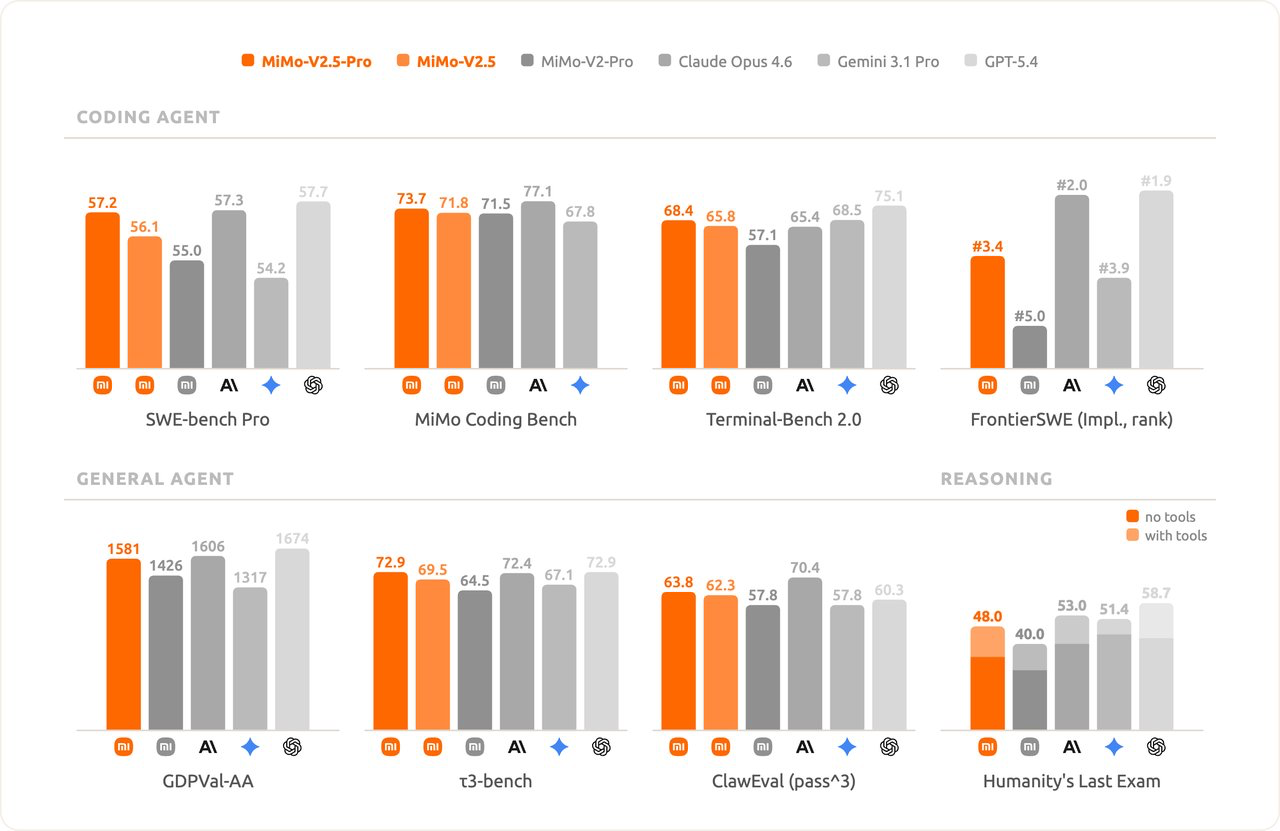
Blog của Xiaomi về bản Pro có mấy chi tiết khá đắt. Quan trọng nhất là họ không né so sánh lớn: thread mở đầu nói thẳng MiMo-V2.5-Pro đang matching frontier models như Claude Opus 4.6 và GPT-5.4 trên phần lớn benchmark chính, từ SWE-bench Pro tới Claw-Eval và τ3-Bench.
Thứ nhất, họ nhấn rất mạnh chuyện 1.000+ tool calls và long-horizon coherence. Đây không còn là kiểu benchmark “trả lời một phát”. Họ muốn chứng minh model giữ được mạch suy nghĩ và kỷ luật thực thi qua những tác vụ kéo dài hàng giờ.
Thứ hai, họ đưa ra các ví dụ rất có chủ đích:
- viết một compiler SysY hoàn chỉnh bằng Rust trong 4.3 giờ với 672 tool calls, pass 233/233 hidden tests,
- xây một video editor desktop hơn 8.000 dòng code qua 1.868 tool calls trong 11.5 giờ,
- tối ưu một bài toán analog EDA qua loop mô phỏng ngspice với Claude Code làm harness.
Ảnh mở đầu từ thread launch: Xiaomi cố đặt MiMo-V2.5-Pro vào cùng khung so sánh với các frontier models.
Điểm quan trọng ở đây không chỉ là “đã làm xong task”. Xiaomi đang cố kể rằng model của họ có harness awareness: biết tận dụng môi trường chạy, biết tự sửa sai, biết chịu đựng những task mà model agent yếu thường tan nát sau vài trăm bước.
Nói thẳng ra, đây là mặt trận mà các model open-weight hay bị nhìn thiếu nghiêm túc. Xiaomi đang cố đập đúng định kiến đó.
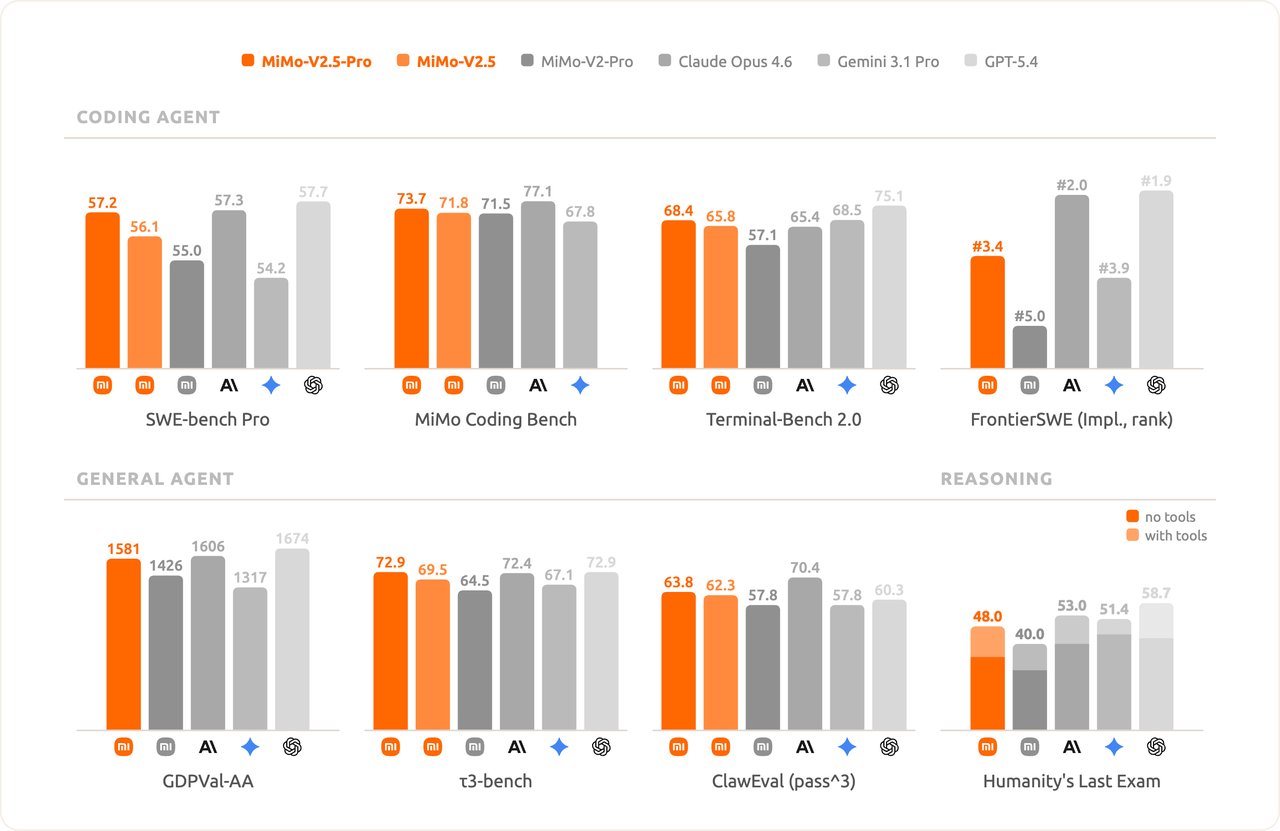
3. Bản thường mới là thứ cho thấy Xiaomi không chỉ nghĩ về benchmark
Nếu bản Pro là cú khoe cơ bắp, thì MiMo-V2.5 bản thường mới là phần nói nhiều về chiến lược sản phẩm.
Bản này có:
- native visual + audio understanding,
- context window lên tới 1M tokens,
- khả năng xử lý image, audio, video trong cùng một model,
- và hiệu năng agent đủ sát bản Pro trong nhiều use case nhưng với chi phí thấp hơn đáng kể.
Ở mảng multimodal, Xiaomi cũng chơi trò so thẳng tay: họ nói MiMo-V2.5 gần như ngang Gemini 3.1 Pro trên Video-MME, bám rất sát ở image understanding, và trên Claw-Eval Multimodal thì chỉ còn kém Claude Opus 4.6 đúng 1 điểm. Đây là kiểu so sánh đủ bắt mắt để kéo click, vì nó đẩy MiMo ra khỏi vùng “model Trung Quốc giá rẻ” sang vùng “model đang chạm bàn của đám frontier thật”.
Đây là kiểu model dễ đi vào use case thật hơn. Vì ngoài một số task coding cực khó, phần lớn production workloads cần một model đủ thông minh, hiểu nhiều modality, phản hồi nhanh và không đốt ngân sách quá hung hãn.
🧠 Angle đáng chú ý nhất của MiMo
MiMo-V2.5 không cố trở thành “mini Pro”. Nó được định vị như model đa dụng để triển khai thật: hiểu ảnh, hiểu video, hiểu audio, chạy agent tốt và giá dễ chịu hơn. Đó là thứ doanh nghiệp quan tâm hơn benchmark screenshot.
4. Điểm Xiaomi đánh mạnh nhất thực ra là token efficiency
Tweet thứ hai trong thread mới là phần đáng tiền nhất. Xiaomi nói rất rõ: ở cùng điểm số Claw-Eval agent benchmark, MiMo-V2.5-Pro dùng ít hơn 42% token so với Kimi K2.6, còn MiMo-V2.5 thì gần như dùng bằng nửa token của Muse Spark.
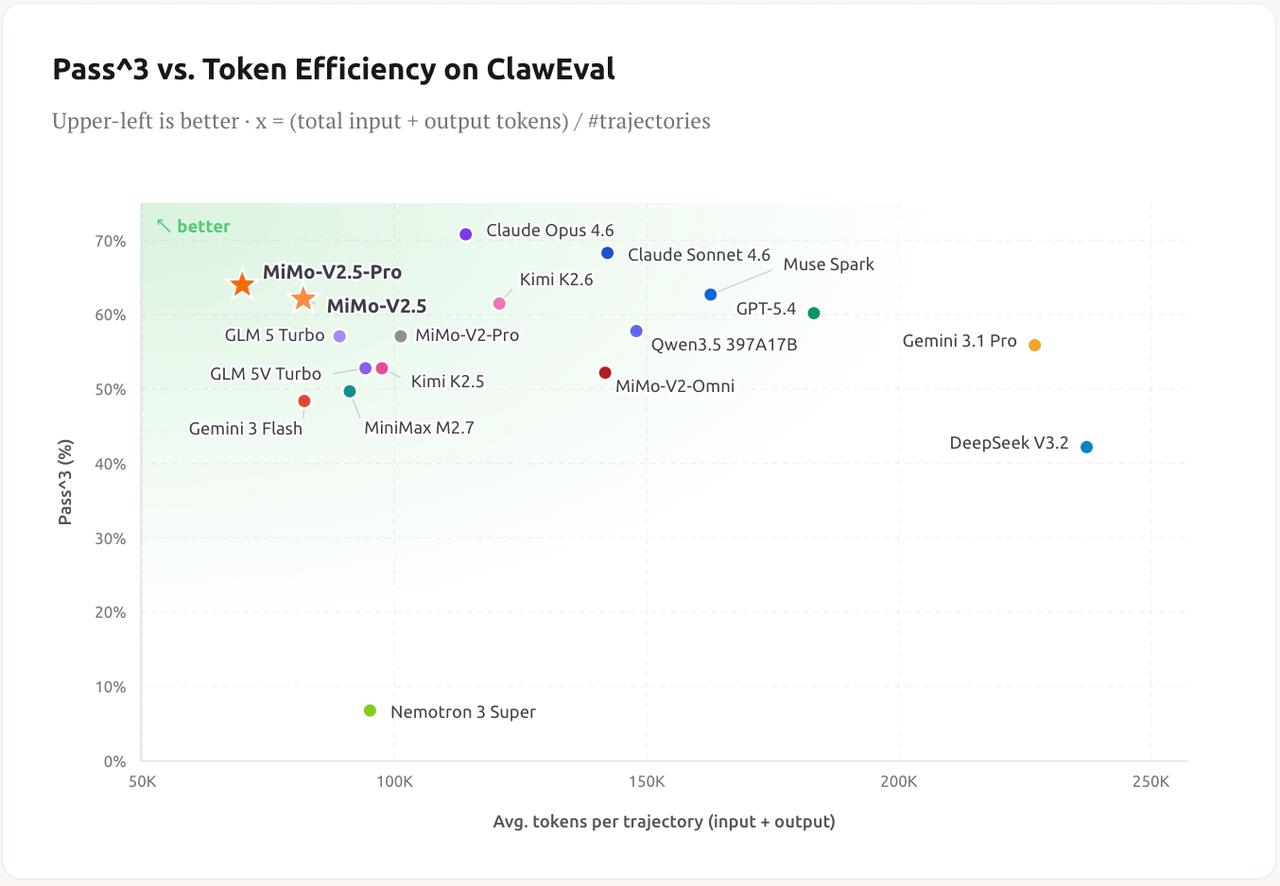
Xiaomi đẩy mạnh luận điểm performance-per-token: cùng benchmark, ít token hơn đồng nghĩa rẻ hơn khi dùng thật.
Đây là shift rất quan trọng. Vì thị trường model đang bắt đầu mệt với benchmark thuần túy. Một model mạnh hơn 1-2 điểm nghe thì vui, nhưng nếu nó ngốn token như quái vật thì đội vận hành sẽ chửi trước khi đội research kịp ăn mừng.
Nói cách khác, Xiaomi đang cố chuyển cuộc tranh luận từ “ai thông minh hơn” sang “ai thông minh đủ mạnh với chi phí hợp lý hơn”. Với mảng agent, đây mới là bài toán đau ví thật sự.
5. Token plan update cho thấy Xiaomi hiểu production pain nằm ở đâu
Xiaomi cũng update luôn token plan:
- MiMo-V2.5: 1x credit
- MiMo-V2.5-Pro: 2x credit
- và đặc biệt: 1M context window không còn bị charge multiplier riêng

Token plan là mảnh rất thực dụng: Xiaomi đang giảm friction cho người muốn dùng long-context và agent workloads thật.
Chi tiết này nghe khô, nhưng thực ra cực kỳ quan trọng. Nếu đúng như Xiaomi nói, họ đang gỡ bớt một trong những thứ khó chịu nhất của long-context workflows: càng nhét nhiều context càng bị phạt giá. Khi bỏ multiplier cho 1M context, họ đang nói với devs rằng cứ dùng cửa sổ ngữ cảnh lớn nếu workflow thật sự cần, đừng sợ hóa đơn vô lý.
6. Nhưng cộng đồng cũng soi ra ngay mấy điểm khó chịu
Phần replies cho thấy launch này không hoàn toàn mượt.
- nhiều người gặp ngay tình trạng link blog bị 404 lúc launch,
- có người hỏi benchmark có phản ánh repo legacy lởm khởm ngoài đời không,
- có người bảo test thực tế thấy model nhanh hơn nhưng dễ sai hơn,
- và cũng có người hỏi token plan có thật sự đáng tiền hay chỉ là đổi tên cách tính.
Đây là phản ứng hoàn toàn bình thường. Cứ model nào khoe “matching Opus, GPT-5.4” là cộng đồng sẽ lập tức bật chế độ ngửi mùi benchmarkmaxxing.
Nhưng điều đáng chú ý là Xiaomi không chỉ khoe chart. Họ có cố dựng một câu chuyện sản phẩm tương đối nhất quán: benchmark, case studies, cost efficiency, token plan, rồi sắp open-source tiếp. Ít nhất, nó có khung chiến lược rõ hơn mấy bài launch chỉ toàn khẩu hiệu.
7. Điểm đáng chú ý hơn cả: Xiaomi đang kéo open-source agents sang một phase mới
Mình nghĩ đây mới là phần quan trọng nhất của câu chuyện.
Trước đây, nhiều model open-weight được nhìn như phương án “rẻ hơn nhưng kém hơn một chút”, hoặc “vui để self-host nhưng chưa chắc đủ cho production khó”. MiMo-V2.5 series đang cố đẩy một luận điểm khác:
- open-source có thể chạm frontier capability,
- agentic tasks có thể được tối ưu nghiêm túc chứ không chỉ benchmark chat,
- và cost efficiency mới là chiến trường quyết định adoption.
Nếu luận điểm này đứng vững, cuộc chơi model sẽ còn ác liệt hơn nhiều. Vì khi khoảng cách chất lượng thu hẹp, bên thắng không chỉ là bên thông minh nhất. Bên thắng là bên làm cho người dùng cảm thấy: “cùng mức đó mà rẻ hơn, nhanh hơn, đỡ tốn token hơn thì tội gì không dùng”.
🎯 Điều Xiaomi đang đánh cược
Model tốt nhất trên giấy chưa chắc là model tốt nhất ngoài đời. Với agent workloads, thứ thắng lâu dài có thể là model giữ được chất lượng đủ cao nhưng ăn ít token hơn, sống khỏe hơn trong harness và bớt làm đội vận hành đau tim hơn.
8. Chốt lại
MiMo-V2.5 và MiMo-V2.5-Pro đáng chú ý không phải vì Xiaomi lại ra thêm một model mới. Chúng đáng chú ý vì Xiaomi đang đánh đúng vào câu hỏi thật của thị trường agent: frontier performance có thể trở nên đủ rẻ và đủ bền để dùng rộng rãi hay chưa?
Họ chưa chứng minh được mọi thứ. Cộng đồng vẫn sẽ còn test, soi và bắt lỗi tiếp. Nhưng angle “open-source agent đang áp sát Claude Opus 4.6, GPT-5.4 và Gemini 3.1 Pro, trong khi ăn ít token hơn” là angle rất mạnh, và thành thật mà nói, hút hơn nhiều so với kiểu launch chỉ chăm chăm khoe benchmark đẹp.
⚙️ Chốt một câu
Xiaomi MiMo-V2.5 không chỉ muốn được xem là model mạnh. Nó muốn được xem là model đủ mạnh để làm việc thật, trong khi vẫn giữ chi phí token ở mức khiến production team không phát điên.
Source: thread của Xiaomi MiMo, blog MiMo-V2.5-Pro, blog MiMo-V2.5 và token plan.