⚡ Tóm tắt nhanh
DeepSeek ra V4 Preview với quy mô 1.6T total / 49B active params ở bản Pro, đi kèm một loạt benchmark đủ rõ để so trực tiếp với nhóm model mạnh nhất hiện tại. DeepSeek-V4-Pro Max đạt 90.2 trên Apex Shortlist và 3206 trên Codeforces — tức là vượt cả Claude Opus 4.6 Max, GPT-5.4 xHigh và Gemini 3.1 Pro High ở các mảng này. Ở SimpleQA Verified, DeepSeek đạt 57.9, hơn Claude và GPT nhưng vẫn sau Gemini. Ở SWE Verified, DeepSeek đạt 80.6, tức là đã bám rất sát nhóm frontier models trong agentic coding.
Điểm đáng chú ý nhất ở V4 Preview không phải riêng con số 1.6T total params hay chuyện DeepSeek tiếp tục open weights. Phần đáng nói hơn là bộ số liệu của họ trải ra đủ rộng để người đọc nhìn model này ở nhiều góc khác nhau: knowledge, reasoning, coding, long context, agentic tasks và pricing.
Nhìn theo từng mảng, DeepSeek đưa ra đủ dữ liệu để đặt V4 cạnh Gemini, GPT, Claude, K2.6 Thinking và GLM-5.1 Thinking. Điều này khiến V4 không chỉ đáng chú ý ở một benchmark lẻ, mà ở chỗ nó có mặt ở nhiều bảng so sánh cùng lúc.
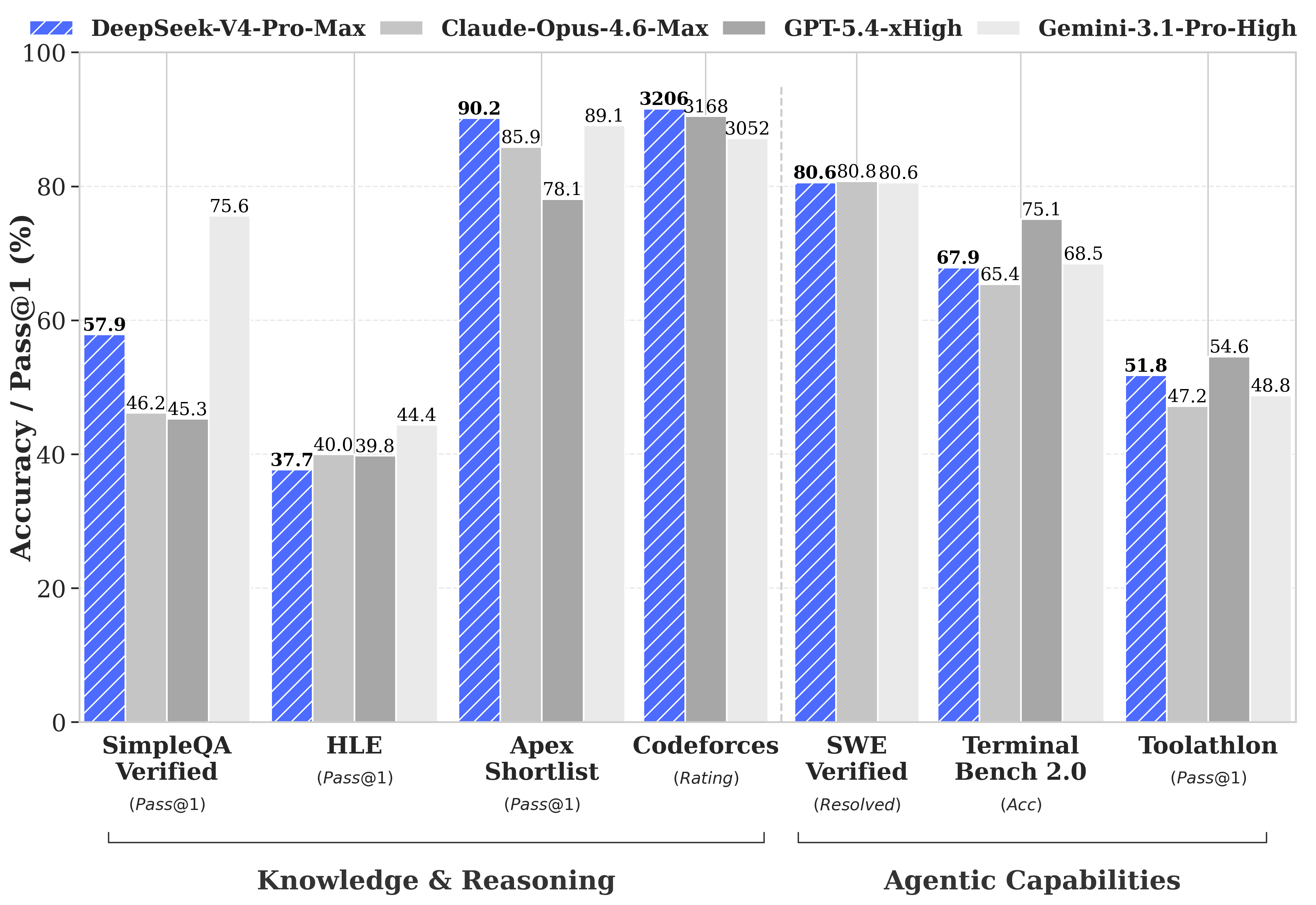
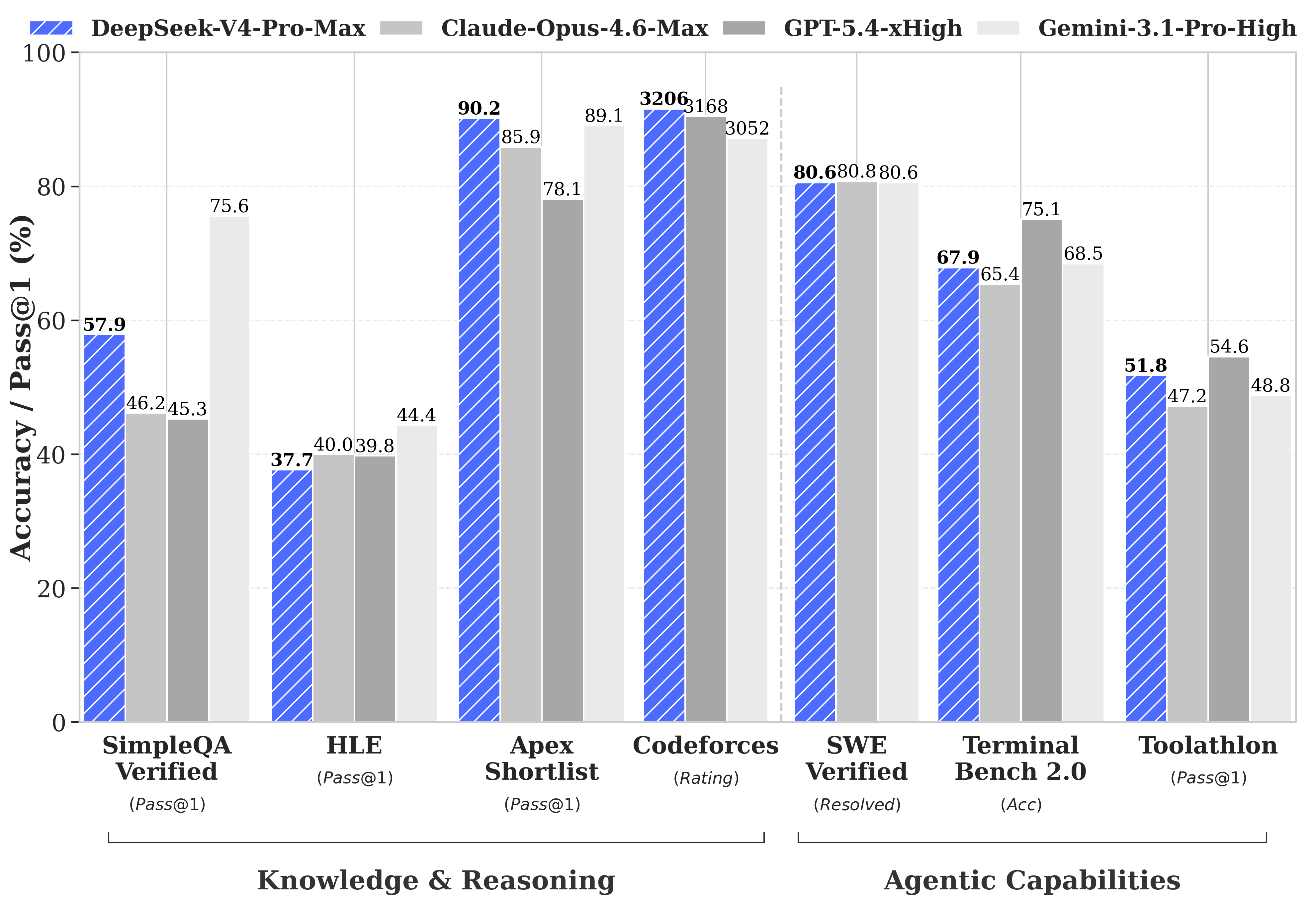
Bảng benchmark này cho thấy DeepSeek so trực diện với Claude Opus 4.6 Max, GPT-5.4 xHigh và Gemini 3.1 Pro High ở nhiều mảng khác nhau, thay vì chỉ xuất hiện ở một benchmark lẻ.
1. DeepSeek đang so với ai ở mảng nào?
DeepSeek không chỉ dừng ở một câu “trail only Gemini 3.1 Pro”. Các số liệu được đưa ra theo ba lớp so sánh song song:
- Nhóm closed / frontier models: Gemini 3.1 Pro High, GPT-5.4 xHigh, Claude Opus 4.6 Max.
- Nhóm open / reasoning models: K2.6 Thinking, GLM-5.1 Thinking.
- Nhóm model cũ của chính DeepSeek: để chứng minh bước nhảy về context efficiency, pricing và deployment path.
Và từng nhóm đối thủ được kéo vào các mảng khác nhau:
- Knowledge & Reasoning: SimpleQA Verified, HLE, Apex Shortlist, Codeforces.
- Agentic Capabilities: SWE Verified, Terminal Bench 2.0, Toolathlon, BrowseComp, MCPAtlas, GDPval-AA.
- Long Context: các bài MRCR 1M, CorpusQA 1M và phần efficiency về FLOPs/KV cache.
- Adoption / API: pricing, 1M context mặc định, compatibility với OpenAI/Anthropic APIs.
2. Ở knowledge, coding và agentic tasks, DeepSeek đang chọn đánh nhiều hướng cùng lúc
Ở bảng benchmark đầu tiên, DeepSeek đem V4-Pro Max so với Claude Opus 4.6 Max, GPT-5.4 xHigh và Gemini 3.1 Pro High trên hai cụm rõ ràng: Knowledge & Reasoning và Agentic Capabilities.
Ảnh này cho thấy vài điểm cực kỳ cụ thể, và đây mới là chỗ nên nhấn:
- Ở SimpleQA Verified, DeepSeek đạt 57.9 — hơn Claude Opus 4.6 Max và GPT-5.4 xHigh, nhưng vẫn thua Gemini 3.1 Pro High. Tức là ở mảng world knowledge kiểu factual QA, Gemini vẫn còn nhỉnh hơn.
- Ở Apex Shortlist, DeepSeek đạt 90.2 và đứng đầu nhóm so sánh. Đây là một trong những điểm đẹp nhất để DeepSeek nói rằng model của họ không chỉ “ổn với open models”, mà còn vượt cả các top model closed ở một benchmark reasoning quan trọng.
- Ở Codeforces, DeepSeek đạt 3206 rating và cũng đứng đầu bảng benchmark này. Đây là số rất đáng đưa lên đầu bài, vì nó giúp claim “beats all current open models in Math/STEM/Coding” bớt mơ hồ hẳn.
- Ở SWE Verified, DeepSeek đạt 80.6. Điểm này không tạo cảm giác hủy diệt toàn bộ đối thủ, nhưng nó cho thấy DeepSeek đã bám rất sát nhóm frontier models ở agentic coding thực chiến.
- Ở Terminal Bench 2.0 và Toolathlon, DeepSeek vẫn chưa đè hết nhóm top closed models. Đây là chỗ nên viết tỉnh táo: DeepSeek mạnh thật, nhưng chưa phải top 1 ở mọi mảng agent.
Nói ngắn gọn: nếu muốn chọn ra mấy con số để đóng đinh vị thế của V4, thì nên lấy 90.2 ở Apex Shortlist, 3206 ở Codeforces và 80.6 ở SWE Verified. Ba số này cho thấy DeepSeek hơn nhóm top model ở một số mảng reasoning/coding cụ thể, chứ không chỉ nói chung chung kiểu “rivaling”.
3. Bảng benchmark rộng hơn mới là chỗ DeepSeek lộ rõ tham vọng
Ở bảng benchmark chi tiết hơn, DeepSeek kéo thêm K2.6 Thinking và GLM-5.1 Thinking vào cùng khung. Điều này cho thấy V4 không chỉ được đem so với nhóm closed frontier models, mà còn được đặt cạnh các open/reasoning rivals đang nổi.
Trong bảng này, DeepSeek-V4-Pro Max thường xuyên nằm top 1 hoặc top 2 ở nhiều benchmark trải dài từ MMLU-Pro, GPQA, LiveCodeBench đến BrowseComp, MCPAtlas và các bài test long context. Điểm nên nhấn ở đây là DeepSeek không chỉ hơn ở một chỗ: họ cố chứng minh rằng mình có thể thắng hoặc bám top ở cả coding, knowledge lẫn agentic tasks.
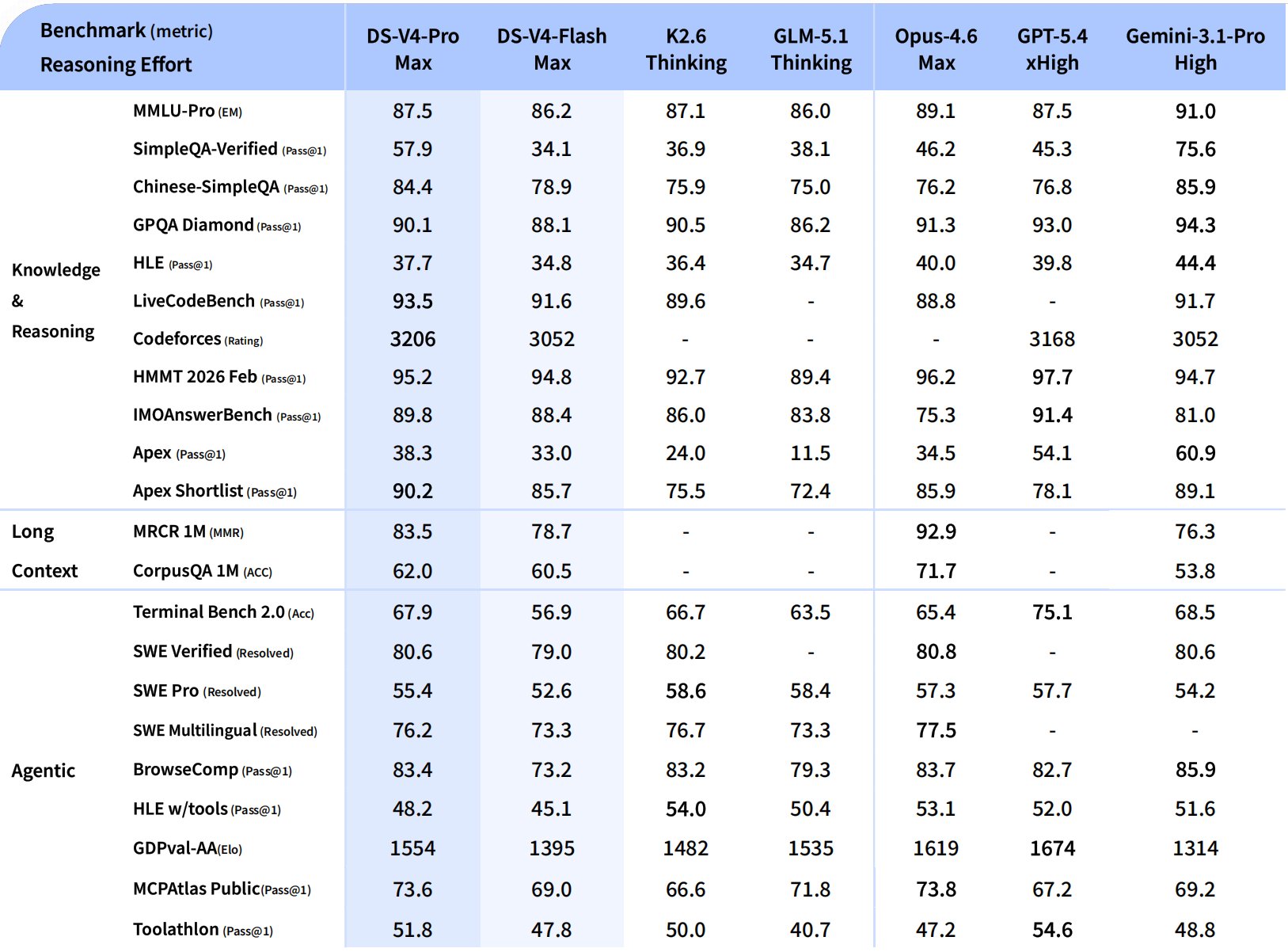
Đây mới là bảng benchmark rộng: DeepSeek kéo thêm K2.6 Thinking, GLM-5.1 Thinking, Claude Opus 4.6 Max, GPT-5.4 xHigh và Gemini 3.1 Pro High vào cùng một mặt bàn để so từng mảng.
Theo chính bảng benchmark này, các con số nổi bật đáng lấy ra để nói thẳng là:
- LiveCodeBench: 93.5 — một điểm rất mạnh ở mảng coding.
- BrowseComp: 83.4 — cho thấy năng lực browse/agent task không chỉ là lời nói suông.
- MCPAtlas: 73.6 — đây là chỉ dấu khá ngon nếu muốn nhấn vào khả năng agent/tool ecosystem.
- MRCR 1M: 83.5 — giúp củng cố claim 1M context không chỉ là marketing headline.
Nói ngắn gọn: DeepSeek có vài điểm thắng rất rõ ở coding và reasoning như Codeforces 3206, Apex 90.2, LiveCodeBench 93.5; đồng thời cũng có thêm các mốc đáng chú ý ở agent/browser/long-context.
4. 1M context chỉ hấp dẫn khi đi kèm efficiency, và DeepSeek biết điều đó
Long context tự nó không còn đủ gây sốc nữa. Người ta nghe 128K, 256K, 1M quá nhiều rồi. DeepSeek hiểu chuyện đó, nên họ không chỉ nói “1M context”, mà nói cost-effective 1M context và “world-leading long context with drastically reduced compute & memory costs”.
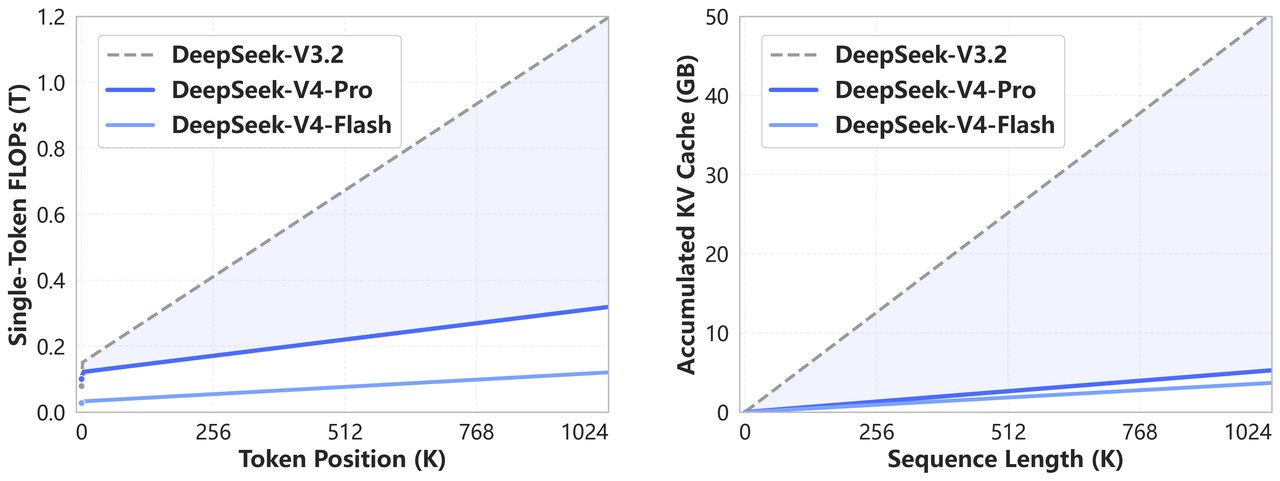
Slide này nói về efficiency thật sự: FLOPs theo token position và KV cache theo sequence length. Ý chính là V4-Pro và nhất là V4-Flash rẻ hơn rõ rệt khi chạy context dài, chứ không chỉ đơn giản là có cửa sổ 1M.
Phần này đến từ hai ý chính:
- token-wise compression,
- và DSA (DeepSeek Sparse Attention).
Nếu chỉ kéo context window lên mà cost và memory usage phình quá mạnh, model rất dễ thành đồ trưng bày. Điểm đáng chú ý ở đây là V4 không chỉ có context dài hơn, mà còn nhấn mạnh hiệu quả compute và memory ở các workflow thật như code, agent loops và document-heavy tasks.
5. Agentic coding mới là thứ DeepSeek muốn lấy làm bàn đạp
DeepSeek cho biết V4 đã được tối ưu riêng cho agent use cases, tích hợp với các agent tools lớn như Claude Code, OpenClaw và OpenCode, đồng thời dùng chính nó cho in-house agentic coding.

Phần này cho thấy DeepSeek đặt V4 vào các workflow agentic coding và tác vụ dài hơi, không chỉ ở chat thông thường.
Đây là điểm đáng để ý hơn nhiều so với mấy câu khoe parameter size. Vì nếu một model open thực sự đủ tốt cho agentic coding, thì nó có thể chen vào nhóm use case mang giá trị rất cao:
- coding agents,
- multi-step tool use,
- PDF/report generation,
- workflow tự động hóa dài hơn chat thông thường.
Nói gọn: DeepSeek đang cố nhảy từ sân benchmark sang sân làm việc thật.
6. V4-Flash mới là phần có thể làm thị trường khó chịu
V4-Pro là flagship. Nhưng V4-Flash mới là phần dễ tạo sức ép hơn về mặt sản phẩm. Điểm chính của Flash không phải là “đứng đầu mọi benchmark”, mà là:
- giữ được một phần đáng kể chất lượng của dòng V4,
- đủ mạnh cho các task nhanh và một phần agent workflow,
- và quan trọng nhất là có profile chi phí/độ trễ hấp dẫn hơn nhiều.
Đây mới là chỗ đáng sợ về mặt sản phẩm: rất nhiều lần thị trường bị hút bởi flagship, nhưng adoption thật lại chạy theo model “đủ giỏi nhưng rẻ và nhanh”. Nếu V4-Flash giữ được chất lượng đủ gần Pro ở các task phổ biến, thì nó có thể trở thành cái tên cực khó chịu trong tầng ứng dụng — không phải vì thắng tuyệt đối benchmark, mà vì tỷ lệ giá / tốc độ / chất lượng quá ổn.
7. Day-0 usability cũng được DeepSeek làm khá bài bản
Một điểm đáng chú ý là DeepSeek đưa model ra cùng với nhiều đường triển khai thực tế:
- chat.deepseek.com với Expert Mode / Instant Mode,
- API update ngay trong ngày,
- hỗ trợ cả OpenAI ChatCompletions lẫn Anthropic APIs,
- thinking / non-thinking modes,
- và roadmap retire các model cũ để ép migration sang V4.
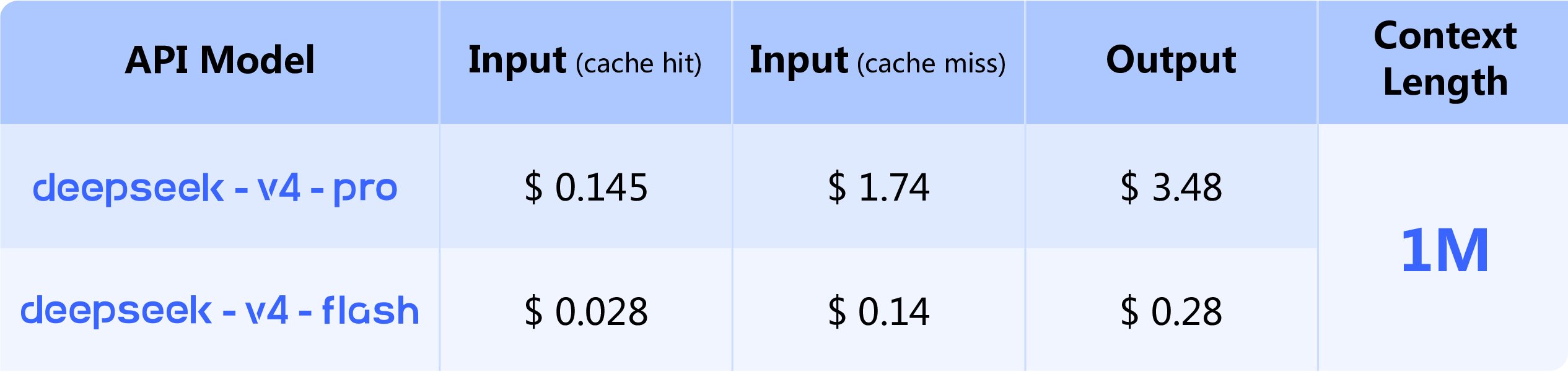
Đây là phần pricing/API, không phải benchmark: DeepSeek chốt luôn giá Pro vs Flash, context 1M và deployment path kiểu giữ base_url, chỉ đổi model.
Đây là phần quan trọng vì rất nhiều model mạnh trên benchmark nhưng chưa dễ dùng ngay. Ở đây DeepSeek đưa luôn pricing và deployment path khá rõ:
- V4-Pro: input miss $1.74, output $3.48,
- V4-Flash: input miss $0.14, output $0.28,
- cả hai đều hỗ trợ 1M context.
Nếu đặt cạnh vài model lớn đang có giá public khá rõ, lợi thế giá của DeepSeek lộ ra rất nhanh:
- Claude Opus 4.7: $5 input / $25 output trên mỗi triệu token.
- Claude Sonnet 4.6: $3 input / $15 output.
- Gemini 3.1 Pro ở text: $0.75 input / $4.50 output trên mỗi triệu token.
So nhanh theo cách dễ hình dung hơn:
- DeepSeek V4-Pro rẻ hơn Claude Opus 4.7 khoảng 2.9 lần ở input ($5 / $1.74) và khoảng 7.2 lần ở output ($25 / $3.48).
- So với Claude Sonnet 4.6, DeepSeek V4-Pro rẻ hơn khoảng 1.7 lần ở input ($3 / $1.74) và khoảng 4.3 lần ở output ($15 / $3.48).
- So với Gemini 3.1 Pro, DeepSeek V4-Pro lại đắt hơn khoảng 2.3 lần ở input ($1.74 / $0.75), nhưng vẫn rẻ hơn khoảng 1.3 lần ở output ($4.50 / $3.48).
- DeepSeek V4-Flash thì ở một tầng giá khác hẳn: so với Claude Opus 4.7, nó rẻ hơn khoảng 35.7 lần ở input và khoảng 89.3 lần ở output; còn so với Gemini 3.1 Pro, nó rẻ hơn khoảng 5.4 lần ở input và khoảng 16.1 lần ở output.
Nhìn theo kiểu này sẽ dễ thấy hơn: V4-Pro đang cố chen vào giữa hiệu năng frontier và giá mềm hơn đáng kể so với Claude, còn V4-Flash thì gần như chơi một game khác hẳn về cost.
8. Chỗ cần tỉnh táo
Dĩ nhiên, vẫn cần dè chừng với mọi model benchmark-heavy. Những câu như “trailing only Gemini 3.1 Pro” hay “rivaling top closed-source models” chỉ thực sự đáng giá nếu model giữ được chất lượng trong điều kiện bẩn hơn ngoài đời: context dài thật, tool loops dài, retrieval tệ, prompt không sạch, và workflow nhiều lỗi lặt vặt.
⚠️ Điều nên soi tiếp
1M context không tự động đồng nghĩa output tốt hơn. Agentic coding benchmark cao cũng chưa chắc translate hoàn hảo sang mọi workflow thực tế. Điểm đáng theo dõi tiếp là context degradation, độ ổn định trong loops dài, và chất lượng tool use khi đụng dữ liệu xấu.
9. Chốt lại
DeepSeek V4 Preview đáng chú ý không chỉ vì open-source hay 1M context. Nó đáng chú ý vì DeepSeek đang đổi cách tự định vị: không còn đóng vai “lựa chọn open rẻ hơn”, mà đang cố chen thẳng vào cuộc chơi giữa các model mạnh nhất.
Và họ làm điều đó bằng một package khá khôn:
- so đối thủ ngay ở đầu, nhưng không chỉ một đối thủ,
- chia benchmark theo nhiều mảng để tự dựng thế trận có lợi,
- đánh cả closed frontier lẫn open reasoning rivals,
- gắn long-context với efficiency thay vì chỉ khoe cửa sổ ngữ cảnh,
- mở weights, và cho API/chat dùng ngay ngày đầu.
🎯 Chốt một câu
DeepSeek V4 Preview không chỉ là một model open mới. Đây là một bản model có đủ số liệu để được đặt cạnh Gemini và nhóm frontier closed-source ở nhiều mảng cùng lúc.
Source: thread của DeepSeek, trang weights trên Hugging Face, và docs DeepSeek API.