⚡ Tóm tắt nhanh
Vals AI vừa đưa DeepSeek V4 lên vị trí #1 open-weight model trên Vibe Code Bench v1.1 với điểm 49.93%. Model đứng thứ hai là Kimi K2.6 chỉ đạt 37.89%, tức DeepSeek hơn tới 12.04 điểm. Sau đó là GLM 5.1 với 31.46%. Điểm đáng nói không chỉ là top 1 open-weight, mà là benchmark này đo khả năng xây ứng dụng web từ đầu bằng pipeline đánh giá tự động tương đối nặng tay.
Post của Vals AI rất thẳng: DeepSeek V4 giờ là open-weight model số 1 trên Vibe Code Benchmark, “and it’s not close”. Câu này nghe hơi mạnh miệng, nhưng nhìn vào chart thì đúng là khoảng cách với model đứng sau không hề nhỏ.
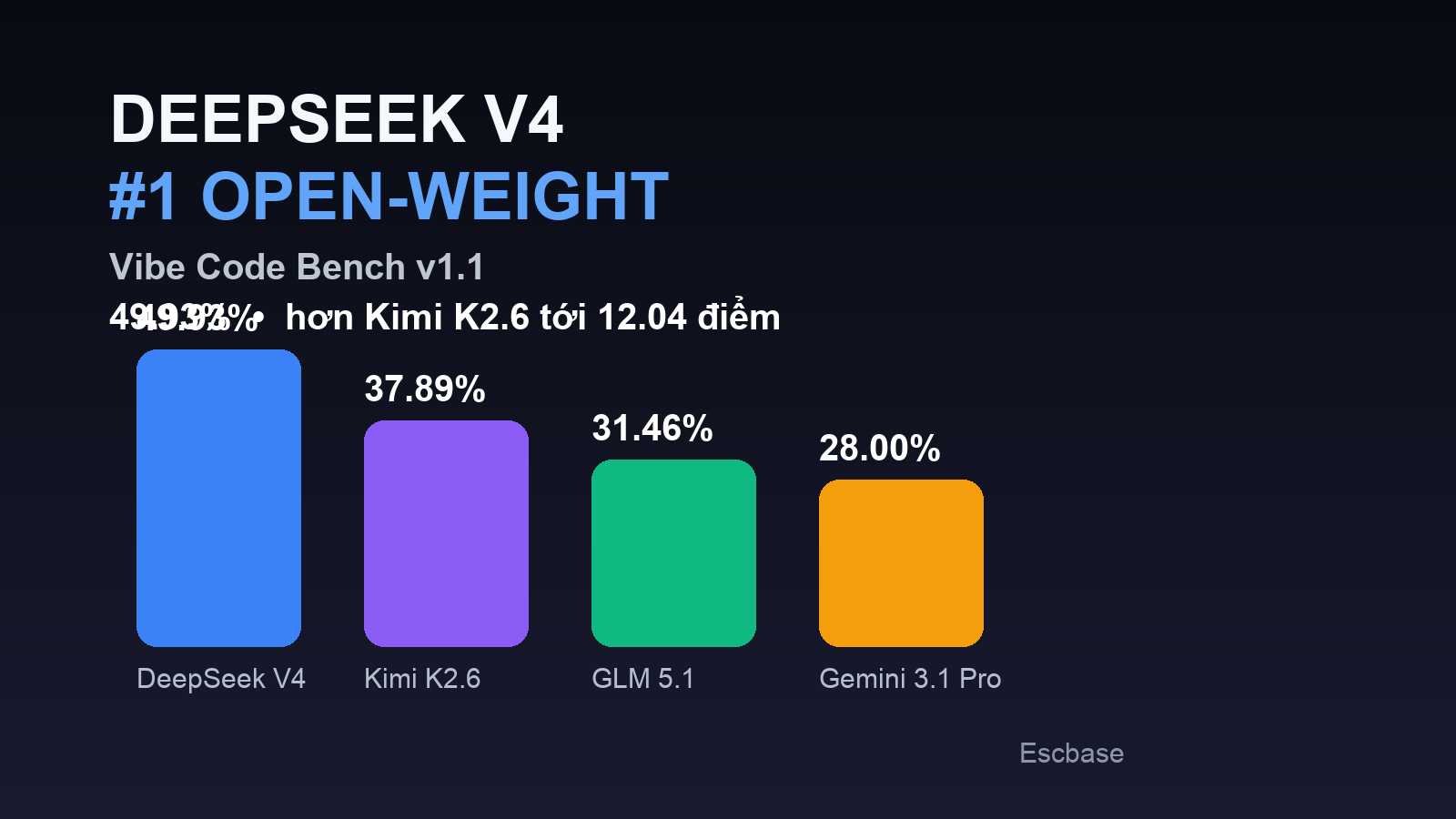
Con số đáng chú ý nhất của chart là khoảng cách giữa DeepSeek V4 và Kimi K2.6: 49.93% so với 37.89%, chênh tới 12.04 điểm.
1. DeepSeek không chỉ đứng đầu open-weight, mà còn bỏ xa phần còn lại
Theo chart Vals AI đăng, top nhóm open-weight hiện tại trên Vibe Code Bench v1.1 trông như sau:
- DeepSeek V4: 49.93% (± 4.77)
- Kimi K2.6: 37.89% (± 4.91)
- GLM 5.1: 31.46% (± 4.55)
- MiniMax-M2.7: 27.04%
- GLM 5: 23.36%
Khoảng cách giữa DeepSeek V4 và Kimi K2.6 là 12.04 điểm. Trong benchmark kiểu này, đó là một khoảng cách khá đáng kể chứ không phải kiểu hơn sát nút 1-2 điểm rồi cãi nhau cả ngày trên X.
2. Benchmark này đo cái gì mà đáng để chú ý?
Điểm đáng để ý là Vibe Code Bench v1.1 không phải benchmark kiểu trả lời trắc nghiệm coding hay giải thuật rời rạc. Theo mô tả của Vals AI, nó nhắm vào câu hỏi thực dụng hơn nhiều:
Liệu model có thể xây một ứng dụng web từ con số 0 hay không?
Pipeline đánh giá của benchmark này chạy tự động từ đầu đến cuối:
- model tạo app theo spec,
- một evaluator model dùng browser-use để chạy test UI,
- scoring được thực hiện tự động,
- và mỗi app đánh giá tiêu tốn khoảng 10-20 USD.
Nói ngắn gọn: đây không phải benchmark rẻ tiền kiểu hỏi model vài câu code rồi chấm bằng regex. Nó cố đo khả năng hoàn thành một nhiệm vụ gần với “làm sản phẩm” hơn.
3. Vì sao kết quả này đáng chú ý hơn một tấm chart khoe top 1?
Vì nếu một model thắng lớn ở benchmark xây web app từ đầu, điều đó gợi ra mấy chuyện:
- nó không chỉ viết code từng đoạn,
- mà còn giữ được mạch nhiều bước,
- chịu được spec có auth/UI/test,
- và ít nhất trên benchmark, đủ ổn để đi từ yêu cầu sang ứng dụng chạy được.
Đó là lý do câu “#1 open-weight model” ở đây có giá trị hơn bình thường. Vì thị trường open-weight lâu nay vẫn hay bị nghi ngờ ở đoạn cuối workflow: viết được demo, nhưng hụt hơi khi phải ghép thành một app hoàn chỉnh.
Nếu kết quả này giữ được khi benchmark được mở rộng thêm, DeepSeek sẽ có một luận điểm rất mạnh: open-weight models không chỉ rẻ hơn, mà còn đủ sức đứng đầu ở loại benchmark gần với công việc thật hơn.
4. Vals AI còn nói DeepSeek vượt cả vài model closed-source
Trong post, Vals AI nói thẳng DeepSeek V4 “even beats out frontier closed source models like Gemini 3.1 Pro”. Đây là claim rất đáng chú ý, dù tấm chart đính kèm đang bật bộ lọc open weights only nên không hiển thị trực tiếp phần so với Gemini.
Điều này có nghĩa là nếu nhìn trên bảng đầy đủ của họ, DeepSeek không chỉ đè nhóm open-weight như Kimi hay GLM, mà còn chen lên trên một số model closed-source mạnh ở chính bài toán build app. Nếu đúng như vậy, đây là một tín hiệu nặng hơn nhiều so với kiểu “open model tốt trong tầm giá”.
5. Chỗ cần giữ đầu lạnh
⚠️ Điều nên nhìn tỉnh
Dù kết quả này rất đẹp cho DeepSeek, đây vẫn chỉ là một benchmark cụ thể với harness, evaluator và scoring riêng của Vals AI. Khoảng sai số đi kèm cũng không nhỏ. Vì vậy, bài học đúng không phải là “DeepSeek đã thắng toàn bộ cuộc chơi coding”, mà là: DeepSeek đang có một kết quả rất mạnh trên một benchmark khá sát bài toán làm app thật, và khoảng cách với nhóm open-weight còn lại hiện đủ lớn để phải chú ý.
6. Chốt lại
Điểm đáng chú ý nhất của post này không chỉ là dòng chữ #1 open-weight model. Cái đáng chú ý hơn là con số:
- DeepSeek V4: 49.93%
- Kimi K2.6: 37.89%
- chênh lệch: 12.04 điểm
Trong một benchmark nhắm vào chuyện xây web app từ đầu, khoảng cách đó đủ lớn để nói rằng DeepSeek V4 hiện không chỉ dẫn đầu open-weight, mà còn đang tạo một khoảng trống khá rõ với phần còn lại.
Nếu các benchmark khác tiếp tục cho kết quả tương tự, câu chuyện lúc này sẽ không còn là “open model đã đuổi kịp chưa”, mà là: model open nào đang thực sự dẫn nhịp ở các workflow coding gần với công việc thật.
Source: post của Vals AI và trang Vibe Code Bench v1.1.